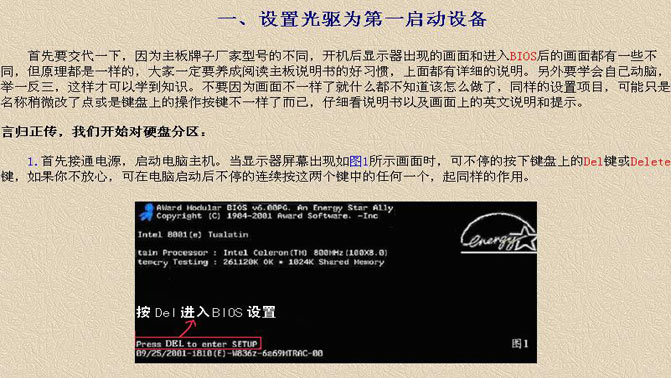
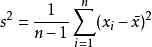1、什么是相關關系
相關分析(correlation analysis),從數量上分析現象之間相關關系的理論和方法。
現象之間的關系可以分為確定關系和非確定性關系。
確定性關系,可以說是函數關系,也就是說對于某一變量的每個數值都有另一變量的完全確定的值與之對應。
非確定性關系,即這里所說的相關關系,現象之間存在一定的依存關系,但不是一一對應的關系,即相隨變動關系。
我們這里探討的就是相關分析。
2、相關關系的分類
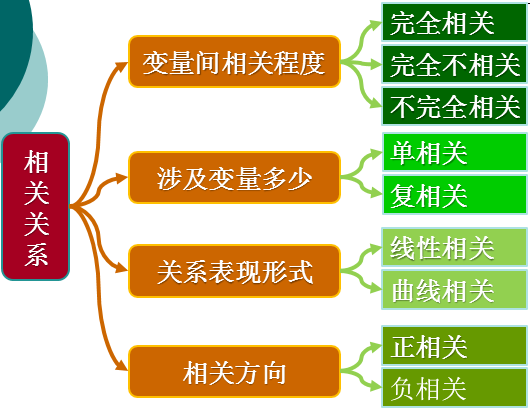
這篇文章主要研究線性相關關系
3、相關分析的基本步驟
(1)繪制散點圖,初步判斷兩個變量之間是否存在某種(線性)有規律的變化;
(2)正態性檢測,如要選擇Pearson相關系數,則要判斷兩個變量是否服從正態分布或近似正態;
(3)計算相關系數,選擇相關的方法公式來計算兩個變量的相關系數r;
(4)顯著性檢驗,判斷這種相關性是否顯著;
(5)給出結論。
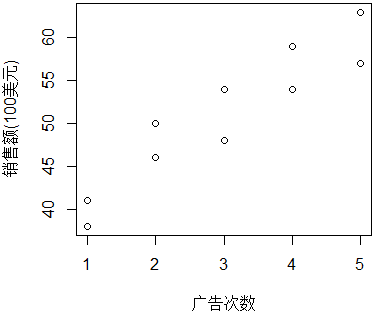
4、散點圖
散點圖可以在坐標系中表示因變量隨自變量而變化的大致趨勢,據此可以選擇合適的函數對數據點進行擬合。在R中繪制散點圖的方法可以參加本站中的另外一篇文章:《使用R語言繪制散點圖》
下圖的散點圖表示了兩個變量之間可能的情況:

5、相關系數
相關系數(CorrelationCoefficient),是專門用來衡量兩個變量之間的線性相關程度的指標,經常用字母r來表示相關系數。
(1)Pearson相關系數
最常用的相關系數,是皮爾遜(Pearson)相關系數,又稱積差相關系數,其公式如下:

(2)Spearman相關系數
用于兩個定序或定類變量的相關程序,對數據分布形態不作要求,也可以用于定序數據,但不如Pearson精確。
秩相關系數的計算步驟如下:
1)把數量標志和品質標志的具體表現按等級次序編號;
2)按順序求出兩個標志的每對等級編號的差;
3)按下式計算相關系數:

其中:秩相關系數記為rs,為兩變量每一對樣本的等級之差,即變量xi與yi的差值,n為樣本容量。
秩相關系數與相關系數一樣,取值-1到+1之間,rs為正時表示正相關,rs為負時表示負相關,rs等于零時表示相關為零。但與相關系數不同的是,它是建立在等級的基礎上計算的,較適用于反映序列變量的相關。
(3)Kendall相關系數
用于反映分類變量一致性的指標,兩個變量均屬于有序分類時使用,Kendall相關系數將在本站另行探討。
相關系數r主要特征有:
(1)取值范圍在[-1,1]之間。
(2)|r|越趨于1,表示線性相關越強;|r|越趨于0,表示線性相關越弱。
(3)若|r|=1,為完全線性相關(相當于兩變量是確定的函數關系)
(4)若r >0,表示兩個變量存在正相關,若r<0,表示兩個變量存在負相關,若r = 0,表示兩個變量不存在線性相關關系。
在實際中,將r分成幾個區間段來表示兩個變量之間的相關強度:
(1)|r|<0.3 相關極弱,為不存在線性相關關系;
(2)0.3 ≤ |r| < 0.5 為低度(弱)線性相關;
(3)0.5 ≤ |r| <0.8為中度(顯著)線性相關;
(4)|r| ≥0.8為高度線性相關。
相關分析與回歸分析在實際應用中有密切關系。然而在回歸分析中,所關心的是一個隨機變量Y對還有一個(或一組)隨機變量X的依賴關系的函數形式。而在相關分析中 ,所討論的變量的地位一樣,分析側重于隨機變量之間的種種相關特征。比如,以X、Y分別記小學生的數學與語文成績,感興趣的是二者的關系怎樣,而不在于由X去預測Y。
在R中可以使用cor函數計算兩組變量之間的相關系數。cor()函數的形式如下:
cor(x, y = NULL, use = "everything", method = c("pearson", "kendall", "spearman"))
其中,x為數值向量、矩陣或數據框;y默認為NULL值,其為與x具有相同的維度;use是對缺失值的處理方式;method給出計算相關系數所使用的方法,即上面所探討的pearson相關系數、spearman相關系數和kendall相關系數。
下面舉例子來說明該函數的具體使用方法:
例1:假設對10戶居民家庭的月可支配收入和消費支出進行調查,得到的原始資料如下:
| 編號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 消費支出 | 20 | 15 | 40 | 30 | 42 | 60 | 65 | 70 | 53 | 78 |
| 可支配收入 | 25 | 18 | 60 | 45 | 62 | 88 | 92 | 99 | 75 | 98 |
那么,居民的消費支出與可支配收入之間是否存在線性相關關系,計算出相關系數并分析。
在R語言中編寫相關程序見下面:
x <- c(25,18,60,45,62,88,92,99,75,98) #定義向量x保存可支配收入
y <- c(20,15,40,30,42,60,65,70,53,78) #定義向量y保存消費支出
#繪制散點圖,看看是否有線性關系
plot(x, y, xlab="可支配收入", ylab="消費支出", main="消費支出與可支配收入的散點圖")
#這樣從散點圖可以看出大致是否成線性關系,是正相關還是負相關
#還可以在散點圖中添加趨勢線,觀察大體趨勢
abline(lm(y~x)) #添加趨勢線,lm()是繪制y與x之間的線性方程
#正態性檢驗
#計算的W值越接近1,表明越接近正態性
shapiro.test(x) #檢驗x是否符合正態分布要求
shapiro.test(y) #檢驗y是否符合正態分布要求
cor(x,y) #計算相關系數,默認采用pearson相關系數
#可以使用method參數指定計算的系數類型
cor(x,y,method='pearson') #pearson法計算的相關系數
#相關性的顯著性檢驗:原假設為變量間不相關
#使用cor.test()函數
cor.test(x,y) #默認使用pearson方法進行檢驗
cor.test(x,y,method="pearson") #可以指定使用pearson方法進行檢驗
繪制的散點圖如下:

添加趨勢線后的散點圖:

正態性檢驗的結果:

正態性原假設為總體服從正態分布,從檢驗結果來看,兩變量的p-value均大于0.05,則在0.05的顯著性水平下,不能拒絕原假設,即認為兩個變量服從正態分布。
相關系數計算結果如下:
0.9877601
可以看出兩個變量具有高度相關性,且相關系數大于0,則居民支出與銷售收入具有高度的正相關性。
顯著性檢驗結果:

從檢驗結果來看,p值<0.05,則在0.05的顯著性水平下,相關系數較顯著。
例2:檢驗智商和其每周花在 電視上的小時數的相關性,其數據如下:

編寫r程序如下:
#定義數據
x <- c(106,86,100,101,99,103,97,113,112,110)
y <- c(7,0,27,50,28,29,20,12,6,17)
#計算相關系數
cor(x,y,method="spearman")
#顯著性檢驗
cor.test(x,y,method="spearman")
相關系數計算結果如下:
-0.1757576
檢驗結果如下圖:

從檢驗結果來看,p值>0.05,則在0.05的顯著性水平下,不能拒絕原假設,則相關系數不夠顯著。
上面的例子有些來源于網絡。
新聞熱點






疑難解答