剛接觸python不久,做一個小項目來練練手。前幾天看了《戰狼2》,發現它在最新上映的電影里面是排行第一的,如下圖所示。準備把豆瓣上對它的影評做一個分析。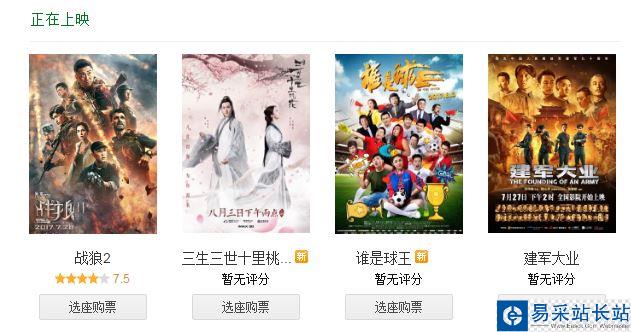
目標總覽
主要做了三件事:
抓取網頁數據 清理數據 用詞云進行展示使用的python版本是3.5.
一、抓取網頁數據
第一步要對網頁進行訪問,python中使用的是urllib庫。代碼如下:
from urllib import requestresp = request.urlopen('https://movie.douban.com/nowplaying/hangzhou/')html_data = resp.read().decode('utf-8')其中https://movie.douban.com/nowp…是豆瓣最新上映的電影頁面,可以在瀏覽器中輸入該網址進行查看。
html_data是字符串類型的變量,里面存放了網頁的html代碼。輸入print(html_data)可以查看,如下圖所示:

第二步,需要對得到的html代碼進行解析,得到里面提取我們需要的數據。在python中使用BeautifulSoup庫進行html代碼的解析。(注:如果沒有安裝此庫,則使用pip install BeautifulSoup進行安裝即可!)BeautifulSoup使用的格式如下:
BeautifulSoup(html,"html.parser")
第一個參數為需要提取數據的html,第二個參數是指定解析器,然后使用find_all()讀取html標簽中的內容。
但是html中有這么多的標簽,該讀取哪些標簽呢?其實,最簡單的辦法是我們可以打開我們爬取網頁的html代碼,然后查看我們需要的數據在哪個html標簽里面,再進行讀取就可以了。如下圖所示:

從上圖中可以看出在div id=”nowplaying“標簽開始是我們想要的數據,里面有電影的名稱、評分、主演等信息。所以相應的代碼編寫如下:
from bs4 import BeautifulSoup as bssoup = bs(html_data, 'html.parser') nowplaying_movie = soup.find_all('div', id='nowplaying')nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item') 其中nowplaying_movie_list 是一個列表,可以用print(nowplaying_movie_list[0])查看里面的內容,如下圖所示:

在上圖中可以看到data-subject屬性里面放了電影的id號碼,而在img標簽的alt屬性里面放了電影的名字,因此我們就通過這兩個屬性來得到電影的id和名稱。(注:打開電影短評的網頁時需要用到電影的id,所以需要對它進行解析),編寫代碼如下:
新聞熱點






疑難解答













