本文記錄了筆者用 Python 爬取淘寶某商品的全過程,并對商品數據進行了挖掘與分析,最終得出結論。
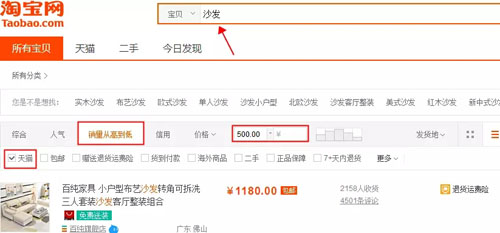
本案例選擇>> 商品類目:沙發;
數量:共100頁 4400個商品;
篩選條件:天貓、銷量從高到低、價格500元以上。
1. 對商品標題進行文本分析 詞云可視化
2. 不同關鍵詞word對應的sales的統計分析
3. 商品的價格分布情況分析
4. 商品的銷量分布情況分析
5. 不同價格區間的商品的平均銷量分布
6. 商品價格對銷量的影響分析
7. 商品價格對銷售額的影響分析
8. 不同省份或城市的商品數量分布
9.不同省份的商品平均銷量分布
注:本項目僅以以上幾項分析為例。
1. 數據采集:Python爬取淘寶網商品數據
2. 對數據進行清洗和處理
3. 文本分析:jieba分詞、wordcloud可視化
4. 數據柱形圖可視化 barh
5. 數據直方圖可視化 hist
6. 數據散點圖可視化 scatter
7. 數據回歸分析可視化 regplot
工具:本案例代碼編輯工具 Anaconda的Spyder
模塊:requests、retrying、missingno、jieba、matplotlib、wordcloud、imread、seaborn 等。
因淘寶網是反爬蟲的,雖然使用多線程、修改headers參數,但仍然不能保證每次100%爬取,所以 我增加了循環爬取,每次循環爬取未爬取成功的頁 直至所有頁爬取成功停止。
說明:淘寶商品頁為JSON格式 這里使用正則表達式進行解析;
代碼如下:
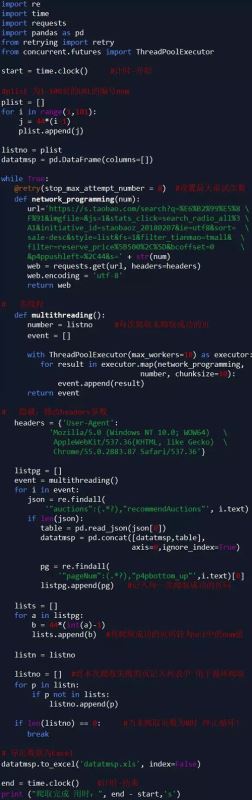
(此步驟也可以在Excel中完成 再讀入數據)
代碼如下:
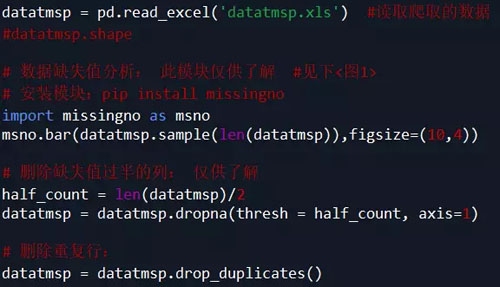
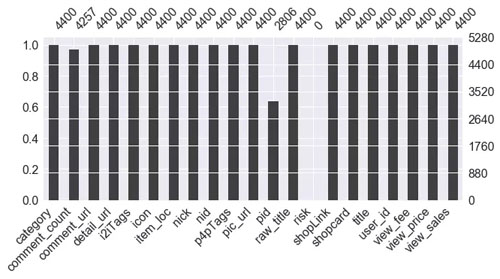
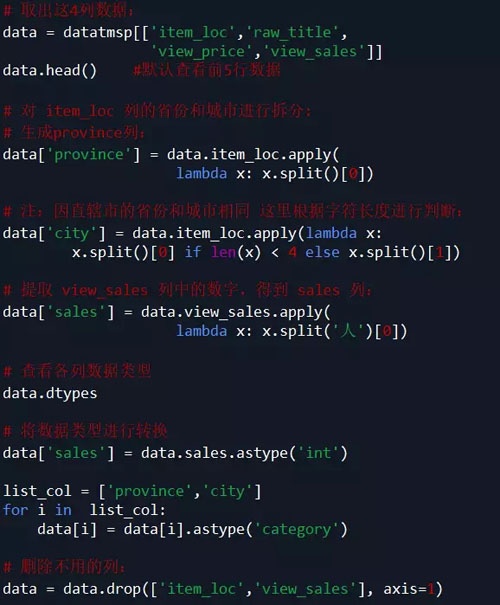
說明:根據需求,本案例中只取了 item_loc, raw_title, view_price, view_sales 這4列數據,主要對 標題、區域、價格、銷量 進行分析。
代碼如下:
【1】. 對 raw_title 列標題進行文本分析:
使用結巴分詞器,安裝模塊pip install jieba
新聞熱點






疑難解答













