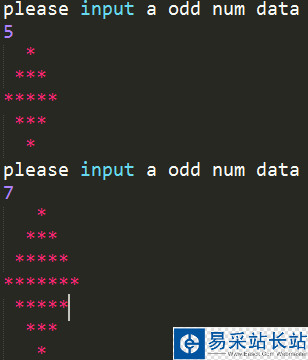
本文研究的主要是Python爬蟲天氣預報的相關內容,具體介紹如下。
這次要爬的站點是這個:http://www.weather.com.cn/forecast/
要求是把你所在城市過去一年的歷史數據爬出來。
分析網站
首先來到目標數據的網頁 http://www.weather.com.cn/weather40d/101280701.shtml
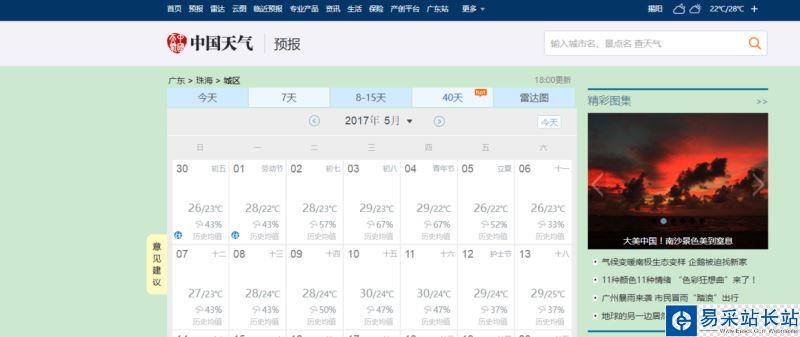
我們可以看到,我們需要的天氣數據都是放在圖表上的,在切換月份的時候,發現只有部分頁面刷新了,就是天氣數據的那塊,而URL沒有變化。
這是因為網頁前端使用了JS異步加載的技術,更新時不用加載整個頁面,從而提升了網頁的加載速度。
對于這種非靜態頁面,我們在請求數據時,就不能簡單的通過替換URL來請求不同的頁面。
著眼點要放在Network,觀察整個請求的過程,從中尋找突破口。
老規矩按下F12 > network,切換下頁面,發現多了一些東西,這就是切換月份,瀏覽器發出的請求,可以很清楚的看到請求頭和請求參數。
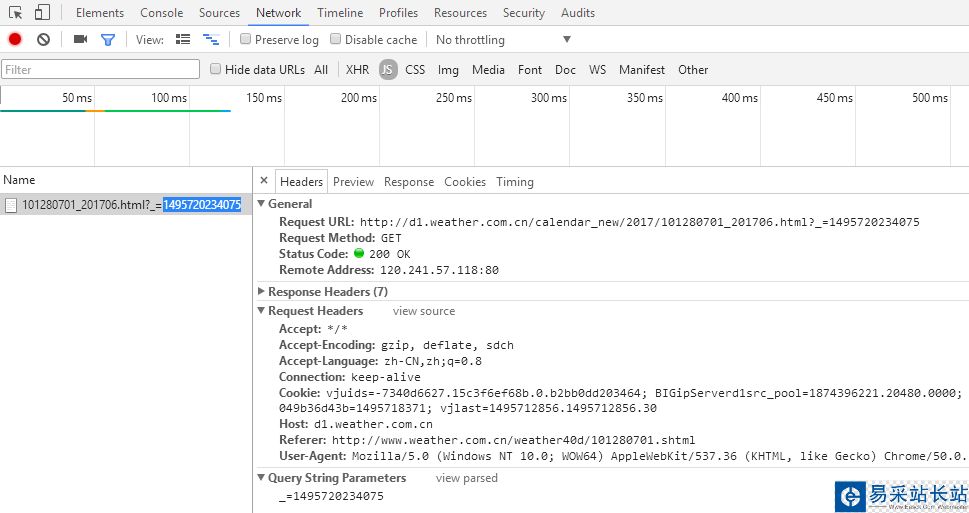
再來看看Response是怎樣的吧

真是沒想到,返回的居然是json格式的天氣數據!直接做 json 反序化就能變成字典的形式,省掉了我們解析 html 的麻煩呀。既然找到了數據所在的地方,就可以開始嘗試構建請求了。
構建請求
先直接copy上面的Request URL,試下請求。http://d1.weather.com.cn/calendar_new/2017/101280701_201706.html?_=1495720234075
然后發現報錯了,先把請求頭全部滿上懟進去,發現可以正常的響應。
但是我們還要分析下到底哪個參數不對出了問題。經過嘗試,發現請求頭里的Referer的原因,去掉就會報錯。
這是因為這是瀏覽器發出請求時,會通過Referer告訴服務器我是從哪個頁面鏈接過來的,有些網站會對這個做驗證,主要時為了防止別人盜鏈的問題。
這個中國天氣網,就是驗證了Referer里的域名是不是自己的,不是的話就會403禁止訪問服務器。
接下來就要考慮怎么請求不同月份的數據。
通過觀察URL,發現其實很簡單,直接替換年月,就可以循環抓取,得到整年的數據。
那中間的101280701是什么意思呢,經過請求不同的城市對比URL,我發現這是表示地理位置的一個數據。
前3位表示國家中國,后6位依次表示,省份,城市和區縣。修改這里,就能實現對不同城市進行查詢了。
最后一個參數1495720234075,開始以為是隨機數,后來有朋友提醒這是unix時間戳,實際上就算去掉這個,也能正常訪問數據,沒什么影響。
新聞熱點






疑難解答