導讀:
隨著大數據概念的火熱,啤酒與尿布的故事廣為人知。我們如何發現買啤酒的人往往也會買尿布這一規律?數據挖掘中的用于挖掘頻繁項集和關聯規則的Apriori算法可以告訴我們。本文首先對Apriori算法進行簡介,而后進一步介紹相關的基本概念,之后詳細的介紹Apriori算法的具體策略和步驟,最后給出Python實現代碼。
1.Apriori算法簡介
Apriori算法是經典的挖掘頻繁項集和關聯規則的數據挖掘算法。A priori在拉丁語中指"來自以前"。當定義問題時,通常會使用先驗知識或者假設,這被稱作"一個先驗"(a priori)。Apriori算法的名字正是基于這樣的事實:算法使用頻繁項集性質的先驗性質,即頻繁項集的所有非空子集也一定是頻繁的。Apriori算法使用一種稱為逐層搜索的迭代方法,其中k項集用于探索(k+1)項集。首先,通過掃描數據庫,累計每個項的計數,并收集滿足最小支持度的項,找出頻繁1項集的集合。該集合記為L1。然后,使用L1找出頻繁2項集的集合L2,使用L2找出L3,如此下去,直到不能再找到頻繁k項集。每找出一個Lk需要一次數據庫的完整掃描。Apriori算法使用頻繁項集的先驗性質來壓縮搜索空間。
2. 基本概念
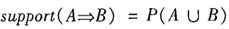
其中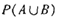 表示事務包含集合A和B的并(即包含A和B中的每個項)的概率。注意與P(A or B)區別,后者表示事務包含A或B的概率。
表示事務包含集合A和B的并(即包含A和B中的每個項)的概率。注意與P(A or B)區別,后者表示事務包含A或B的概率。
置信度(confidence):關聯規則的置信度定義如下:
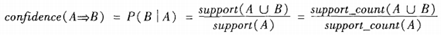
項集的出現頻度(support count):包含項集的事務數,簡稱為項集的頻度、支持度計數或計數。
頻繁項集(frequent itemset):如果項集I的相對支持度滿足事先定義好的最小支持度閾值(即I的出現頻度大于相應的最小出現頻度(支持度計數)閾值),則I是頻繁項集。
強關聯規則:滿足最小支持度和最小置信度的關聯規則,即待挖掘的關聯規則。
3. 實現步驟
一般而言,關聯規則的挖掘是一個兩步的過程:
新聞熱點






疑難解答













