k-近鄰算法概述:
所謂k-近鄰算法KNN就是K-Nearest neighbors Algorithms的簡稱,它采用測量不同特征值之間的距離方法進行分類
用官方的話來說,所謂K近鄰算法,即是給定一個訓練數據集,對新的輸入實例,在訓練數據集中找到與該實例最鄰近的K個實例(也就是上面所說的K個鄰居), 這K個實例的多數屬于某個類,就把該輸入實例分類到這個類中。
k-近鄰算法分析
優點:精度高、對異常值不敏感、無數據輸入假定。
缺點:計算復雜度高、空間復雜度高。
適用數據范圍:數值型和標稱型
k-近鄰算法工作原理:
它的工作原理是:存在一個樣本數據集合,也稱作訓練樣本集,并且樣本集中每個數據都存在標簽,即我們知道樣本集中每一數據與所屬分類的對應關系。輸入沒有標簽的新數據后,將新數據的每個特征與樣本集中數據對應的特征進行比較,然后算法提取樣本集中特征最相似數據(最近鄰)的分類標簽。一般來說,我們只選擇樣本數據集中前k個最相似的數據,這就是k-近鄰算法中k的出處,通常k是不大于20的整數。最后,選擇k個最相似數據中出現次數最多的的分類,作為新數據的分類。
k-近鄰算法實現過程:
對未知類別屬性的數據集中的每個點依次執行以下操作:
(1)計算已知類別數據集中的點與當前點之間的距離;
(2)按照距離遞增次序排序;
(3)選取與當前點距離最小的k個點;
(4)確定前k個點所在類別的出現頻率;
(5)返回前k個點出現頻率最高的類別作為當前點的預測分類。
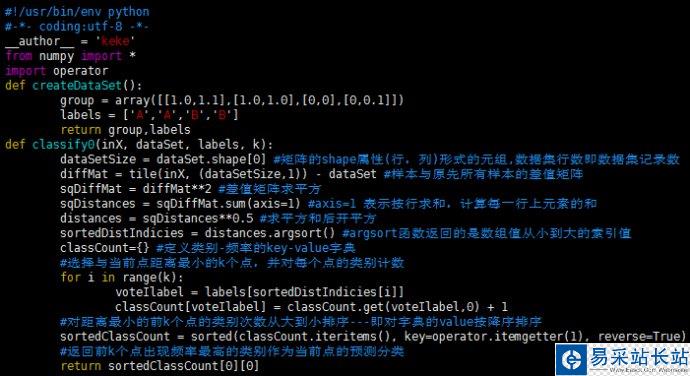
k-近鄰算法python代碼實現:
編輯kNN.py文件代碼如下:
編輯完成后保存,linux下確保當前路徑為存儲kNN.py文件的位置,進入python開發環境開始測試:
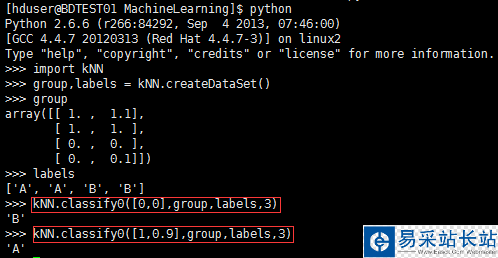
上圖給出了點[0,0]、[1,0.9]的測試輸出分類結果分別為B、A。至此,我們已經構造完成了一個分類器,使用這個分類器可以完成很多分類任務。從這個實例出發,構造使用分類算法將會更加容易。
分類器測試評估:
為了測試分類器的效果,需要對分類器做出評估,我們可以通過大量的測試數據得到分類器的錯誤率——分類器給出錯誤結果的次數除以測試執行的總數。錯誤率是常用的評估方法,主要用于評估分類器在某個數據集上的執行效果。完美分類器的錯誤率為0,最差分類器的錯誤率是1.0,在這種情況下,分類器根本就無法找到一個正確答案。
新聞熱點






疑難解答













