K-means算法簡介
K-means是機器學習中一個比較常用的算法,屬于無監督學習算法,其常被用于數據的聚類,只需為它指定簇的數量即可自動將數據聚合到多類中,相同簇中的數據相似度較高,不同簇中數據相似度較低。
K-MEANS算法是輸入聚類個數k,以及包含 n個數據對象的數據庫,輸出滿足方差最小標準k個聚類的一種算法。k-means 算法接受輸入量 k ;然后將n個數據對象劃分為 k個聚類以便使得所獲得的聚類滿足:同一聚類中的對象相似度較高;而不同聚類中的對象相似度較小。
核心思想
通過迭代尋找k個類簇的一種劃分方案,使得用這k個類簇的均值來代表相應各類樣本時所得的總體誤差最小。
k個聚類具有以下特點:各聚類本身盡可能的緊湊,而各聚類之間盡可能的分開。
k-means算法的基礎是最小誤差平方和準則,K-menas的優缺點:
優點:
原理簡單
速度快
對大數據集有比較好的伸縮性
缺點:
需要指定聚類 數量K
對異常值敏感
對初始值敏感
K-means的聚類過程
其聚類過程類似于梯度下降算法,建立代價函數并通過迭代使得代價函數值越來越小
適當選擇c個類的初始中心;
在第k次迭代中,對任意一個樣本,求其到c個中心的距離,將該樣本歸到距離最短的中心所在的類;
利用均值等方法更新該類的中心值;
對于所有的c個聚類中心,如果利用(2)(3)的迭代法更新后,值保持不變,則迭代結束,否則繼續迭代。
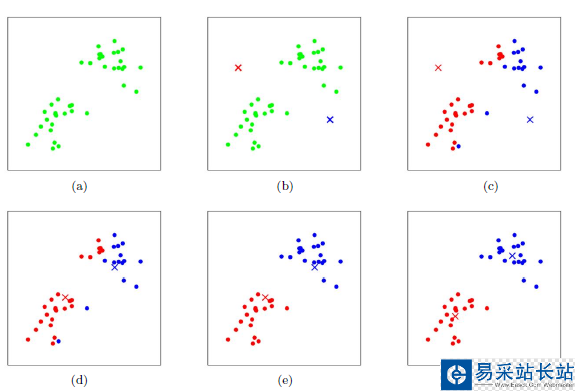
該算法的最大優勢在于簡潔和快速。算法的關鍵在于初始中心的選擇和距離公式。
K-means 實例展示
python中km的一些參數:
sklearn.cluster.KMeans( n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto' )n_clusters: 簇的個數,即你想聚成幾類init: 初始簇中心的獲取方法n_init: 獲取初始簇中心的更迭次數,為了彌補初始質心的影響,算法默認會初始10個質心,實現算法,然后返回最好的結果。max_iter: 最大迭代次數(因為kmeans算法的實現需要迭代)tol: 容忍度,即kmeans運行準則收斂的條件precompute_distances:是否需要提前計算距離,這個參數會在空間和時間之間做權衡,如果是True 會把整個距離矩陣都放到內存中,auto 會默認在數據樣本大于featurs*samples 的數量大于12e6 的時候False,False 時核心實現的方法是利用Cpython 來實現的verbose: 冗長模式(不太懂是啥意思,反正一般不去改默認值)random_state: 隨機生成簇中心的狀態條件。copy_x: 對是否修改數據的一個標記,如果True,即復制了就不會修改數據。bool 在scikit-learn 很多接口中都會有這個參數的,就是是否對輸入數據繼續copy 操作,以便不修改用戶的輸入數據。這個要理解Python 的內存機制才會比較清楚。n_jobs: 并行設置algorithm: kmeans的實現算法,有:'auto', ‘full', ‘elkan', 其中 ‘full'表示用EM方式實現雖然有很多參數,但是都已經給出了默認值。所以我們一般不需要去傳入這些參數,參數的。可以根據實際需要來調用。
新聞熱點






疑難解答













