本文實例講述了Android編程簡易實現XML解析的方法。分享給大家供大家參考,具體如下:
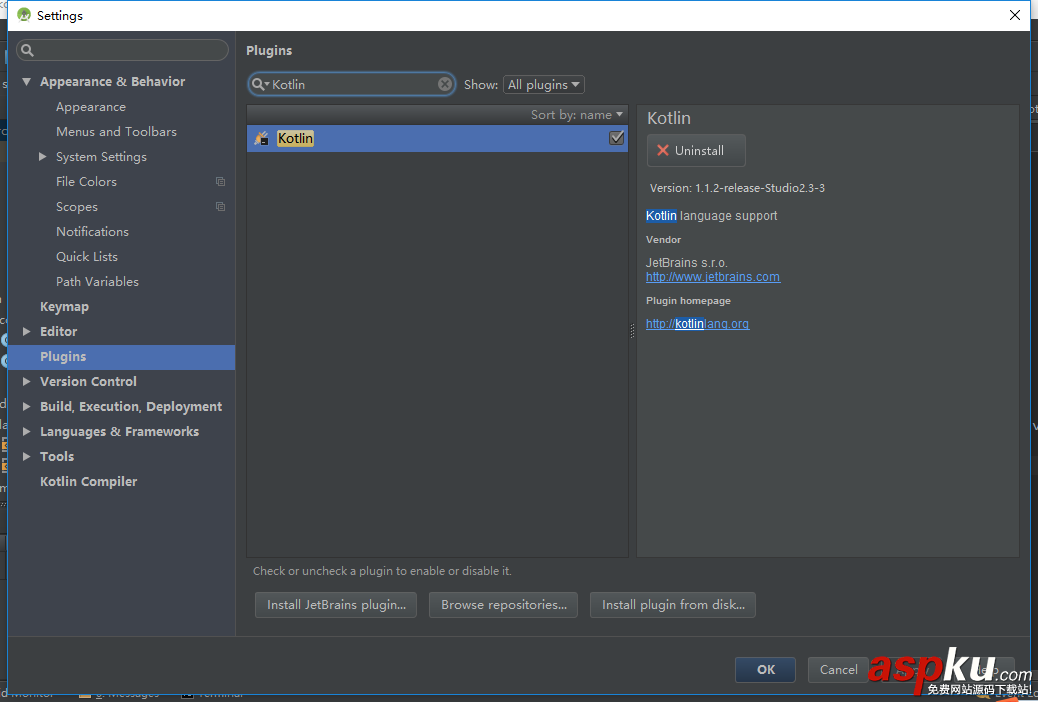
首先創建在Android工程中創建一個Assets文件夾 app/src/main/assets

在這里添加一個名為 data.xml的文件,然后編輯這個文件,加入如下XML格式內容
<?xml version="1.0" encoding="utf-8"?><apps> <app> <id>1</id> <name>Google Maps</name> <version>1.0</version> </app> <app> <id>2</id> <name>Chrome</name> <version>2.1</version> </app> <app> <id>3</id> <name>Google play</name> <version>2.3</version> </app></apps>
==============獲取XML中內容================
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); try { //獲取XML文件的輸入流 InputStream fis = getResources().getAssets().open("data.xml"); InputStreamReader isr = new InputStreamReader(fis, "UTF-8"); StringBuffer stringBuffer = new StringBuffer(); int mark = -1; while ((mark = isr.read()) != -1) { stringBuffer.append((char) mark); } String data = stringBuffer.toString(); //把整個文件內容以String方式傳入 //parseXMLWithPull(data); //parseXMLWithSAX(data); } catch (IOException e) { e.printStackTrace(); } }==============Pull解析方式=================
獲取解析工具XmlPullParser:
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();XmlPullParser xmlPullParser = factory.newPullParser();
傳入XML字符流:
xmlPullParser.setInput(new StringReader(xmlData));
根據節點特征進行處理:
switch ( xmlPullParser.getEventType() )
private void parseXMLWithPull(String xmlData) { try { XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); XmlPullParser xmlPullParser = factory.newPullParser(); xmlPullParser.setInput(new StringReader(xmlData)); int eventType = xmlPullParser.getEventType(); String id = ""; String name = ""; String version = ""; while (eventType != xmlPullParser.END_DOCUMENT) { String nodeName = xmlPullParser.getName(); switch (eventType) { //開始解析某個節點 case XmlPullParser.START_TAG: { if ("id".equals(nodeName)) { id = xmlPullParser.nextText(); } else if ("name".equals(nodeName)) { name = xmlPullParser.nextText(); } else if ("version".equals(nodeName)) { version = xmlPullParser.nextText(); } } break; //完成解析某個節點 case XmlPullParser.END_TAG: { if ("app".equals(nodeName)) { Log.d("woider", "id is " + id); Log.d("woider", "name is " + name); Log.d("woider", "version is " + version); } } break; } eventType = xmlPullParser.next(); } } catch (Exception e) { e.printStackTrace(); } }==============SAX解析方式=================
使用SAX解析通常需要創建一個類繼承DefaultHandler,并重寫父類的五個方法
startDocument():開始XML解析的時候調用
startElement():開始解析某個結點的時候調用
characters():獲取節點中內容的時候調用
endElement():完成解析某個節點的時候調用
endDocument():完成整個XML解析的時候調用
public class ContentHandler extends DefaultHandler { private String nodeName; private StringBuilder id; private StringBuilder name; private StringBuilder version; @Override public void startDocument() throws SAXException { id = new StringBuilder(); name = new StringBuilder(); version = new StringBuilder(); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //記住當前結點名 nodeName = localName; } @Override public void characters(char[] ch, int start, int length) throws SAXException { //進行格式規范化 String str = new String(ch, start, length).trim(); //根據當前節點名添加內容 if ("id".equals(nodeName)) { id.append(str); } else if ("name".equals(nodeName)) { name.append(str); } else if ("version".equals(nodeName)) { version.append(str); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { if ("app".equals(localName)) { Log.d("woider", "id is " + id); Log.d("woider", "name is " + name); Log.d("woider", "version is " + version); //清空StringBuilder id.setLength(0); name.setLength(0); version.setLength(0); } } @Override public void endDocument() throws SAXException { }}獲取解析工具XMLReader:
SAXParserFactory factory = SAXParserFactory.newInstance();XMLReader xmlReader = factory.newSAXParser().getXMLReader();
傳入規則到解析工具:
ContentHandler handler = new ContentHandler();xmlReader.setContentHandler(handler);
開始執行解析:
xmlReader.parse(new InputSource(new StringReader(xmlData)));
private void parseXMLWithSAX(String xmlData) { try { SAXParserFactory factory = SAXParserFactory.newInstance(); XMLReader xmlReader = factory.newSAXParser().getXMLReader(); ContentHandler handler = new ContentHandler(); //將ContentHandler的實例設置到XMLReader中 xmlReader.setContentHandler(handler); //開始執行解析 xmlReader.parse(new InputSource(new StringReader(xmlData))); } catch (Exception e) { e.printStackTrace(); } }方法二(直接針對InputStream解析)
獲取解析工具SAXParser:
SAXParserFactory factory = SAXParserFactory.newInstance();SAXParser parser = factory.newSAXParser();
獲取規則和輸入流:
handler = new ParserHandler();InputStream inputStream = getResources().getAssets().open("data.xml");同時傳入開始解析:
parser.parse(inputStream, handler);
最后打印 LogCat 中的日志,data.xml的解析就完成了

除了 Pull 解析和 SAX 解析之外,還有一種 DOM 解析也非常重要。
另外還有一些XML解析工具,比如 JDOM 和 DOM4J,它們簡化了解析的步驟,提高了解析的效率。
希望本文所述對大家Android程序設計有所幫助。
新聞熱點






疑難解答