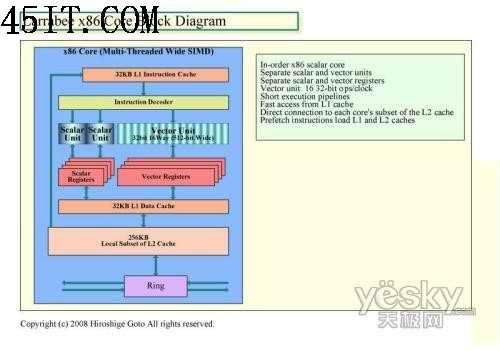
傳統(tǒng)的x86架構(gòu)
而Larrabee基于傳統(tǒng)的x86架構(gòu),是一種可編程的多核心架構(gòu),不同的版本會有不同數(shù)量的核心,并使用經(jīng)過調(diào)整的x86指令集,性能上將會達(dá)到萬億次浮點運算級別。值得注意的是,Larrabee中的處理核心為順序執(zhí)行核心,與CPU中的亂序執(zhí)行核心不同。
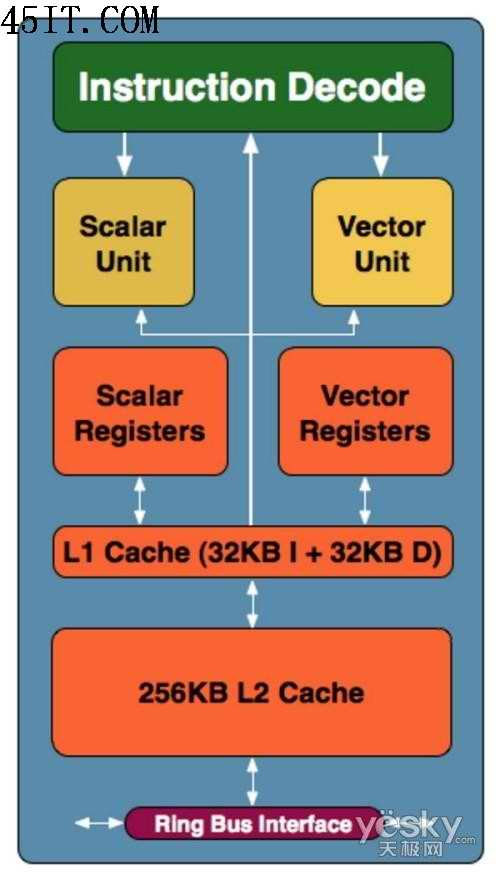
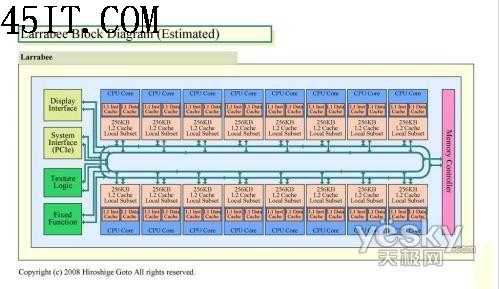
Larrabee內(nèi)部工作流程
在Larrabee的內(nèi)部,每一個處理核心都可以發(fā)出2條指令,這種架構(gòu)是繼承了最初的奔騰處理器的設(shè)計。當(dāng)然在老奔騰的基礎(chǔ)上,INTEL的工程師們也作了許多修改和提升。首先Larrabee 架構(gòu)具有衍生自雙指令執(zhí)行 Pentium 處理器的純量管線,并采用具有完整連貫性高速緩存架構(gòu)的短執(zhí)行管線。Larrabee 架構(gòu)提供顯著的最新改良技術(shù),如寬幅向量處理單元、多線程、64 位延伸指令,以及精密的指令預(yù)取功能 。這將促使可用之運算能力大幅提升,并能發(fā)揮程序設(shè)計師對英 特爾架構(gòu)的熟悉度及容易入門的程序開發(fā)優(yōu)勢。同時Larrabee的執(zhí)行流水線階層非常的短,最初的Pentium處理器的執(zhí)行流水線僅有5個階層,這意味著擁有不錯的運算效率。Larrabee 將包含數(shù)個支持繪圖及其他應(yīng)用程序的固定功能邏輯區(qū)塊,這些運算單元被謹(jǐn)慎選用以平衡及強化每瓦效能,并對架構(gòu)的彈性與可編程化能力有所貢獻(xiàn)。Larrabee 的原生程序設(shè)計模式支持高度平行運算應(yīng)用程序,亦包括采用非規(guī)則性數(shù)據(jù)結(jié)構(gòu)的運算。這項特性將促使繪圖 API 的開發(fā)、新繪圖算法更迅速的創(chuàng)新,以及在繪圖處理器上執(zhí)行以現(xiàn)有個人計算機軟件開發(fā)工具軟件所實作 之真正的一般目的運算。
邏輯處理單元的分布
在算矢量處理單元的部分。Pentium由于設(shè)計年代久遠(yuǎn),未曾出現(xiàn)過SIMD單指令多數(shù)據(jù)單元,而Larrabee在這方面有了巨大的飛躍,支持16路的矢量ALU算數(shù)邏輯單元。其運算效能非常強大,這16路可以同時執(zhí)行32bit的浮點操作,這比INTEL所生產(chǎn)過的任何處理器都要強大許多。介于Larrabee本身的架構(gòu)優(yōu)勢,這些矢量單元會更好的發(fā)揮其作用。INTEL的工程師們在指令的預(yù)取方面會為Larrabee做更多海量并行數(shù)據(jù)處理方面的優(yōu)化。但究竟會對實際的效能產(chǎn)生多大的影響,目前仍是個迷。Larrabee所有超強的性能,都是基于這16路矢量ALU邏輯運算單元。請記住!這僅僅是Larrabee的一個核心,當(dāng)它用于處理3D圖像的時候,其內(nèi)部還有很多的核心在并行工作。
此外,INTEL還對Larrabee架構(gòu)指令集擴展進(jìn)行了優(yōu)化改進(jìn)。比如16-Widevector指令,streamprocessing最佳化緩存控制指令等。另外64-bit指令也得到了支持。簡單得說就是以x86基本指令集為基礎(chǔ)加上適當(dāng)?shù)膕tream processing指令。另外據(jù)說當(dāng)前的GPU原生指令集與CPU指令集非常相似。INTEL關(guān)于Larrabee指令擴展并沒有進(jìn)行詳細(xì)介紹。不過估計可以有點,首先就是指令格式必須容易解碼。x86指令解碼多且復(fù)雜。因此為了解決這個問題,Larrabee的擴張指令最好是固定長度指令。
GPU也有L2緩存?!
由于基于Pentium 處理器架構(gòu),因此Larrabee同樣沿用了完整的L1/L2緩存設(shè)計,這也是目前GPU所不具備的。
Pentium處理器架構(gòu)
在L1高速緩存容量方面,其中指令緩存為32KB,L1數(shù)據(jù)緩存為32KB和,這個比各自為8KB的Pentium處理器相比提升了4倍。 同時每一個處理核心都具備256KB的L2高速緩存,未來Larrabee最初的二級緩存容量為4M,這意味著Larrabee最少有16個內(nèi)核。
INTEL Core 2 Duo Hypothetical Larrabee
# of CPU Cores 2 out of order 10 in-order
Instructions per Issue 4 per clock 2 per clock
VPU Lanes per Core 4-wide SSE 16-wide
L2 Cache Size 4MB 4MB
Single-Stream Throughput 4 per clock 2 per clock
Vector Throughput 8 per clock 160 per clock
根據(jù)INTEL所述,這種256KB的緩存尺寸是專門針對Larrabee所設(shè)計的。一般來說在Larrabee進(jìn)行OpenGL/DirectX渲染的時候,許多紋理都是基于64X64或128X128像素規(guī)格的,他們的色深一般為32bit,另帶有32bit的Z緩沖,這些大約會消耗128KB的空間,同時Larrabee的處理核心還有128KB的空間可以加載其他的數(shù)據(jù)。
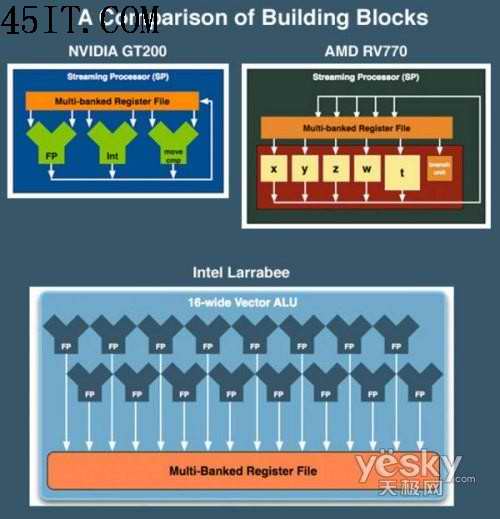
AMD RV770 NVIDIA GT200 INTEL Larrabee
Scalar ops per L1 Cache 80 24 16
L1 Cache Size 16KB unknown 32KB
Scalar ops per L2 Cache 100 30 16
L2 Cache Size unknown unknown 256KB
新聞熱點





疑難解答
圖片精選