關聯規則挖掘(Association rule mining)是數據挖掘中最活躍的研究方法之一,可以用來發現事情之間的聯系,最早是為了發現超市交易數據庫中不同的商品之間的關系。(啤酒與尿布)
基本概念
1、支持度的定義:support(X-->Y) = |X交Y|/N=集合X與集合Y中的項在一條記錄中同時出現的次數/數據記錄的個數。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同時出現的次數/數據記錄數 = 3/5=60%。
2、自信度的定義:confidence(X-->Y) = |X交Y|/|X| = 集合X與集合Y中的項在一條記錄中同時出現的次數/集合X出現的個數 。例如:confidence({啤酒}-->{尿布}) = 啤酒和尿布同時出現的次數/啤酒出現的次數=3/3=100%;confidence({尿布}-->{啤酒}) = 啤酒和尿布同時出現的次數/尿布出現的次數 = 3/4 = 75%
同時滿足最小支持度閾值(min_sup)和最小置信度閾值(min_conf)的規則稱作強規則 ,如果項集滿足最小支持度,則稱它為頻繁項集
“如何由大型數據庫挖掘關聯規則?”關聯規則的挖掘是一個兩步的過程:
1、找出所有頻繁項集:根據定義,這些項集出現的頻繁性至少和預定義的最小支持計數一樣。
2、由頻繁項集產生強關聯規則:根據定義,這些規則必須滿足最小支持度和最小置信度。
Apriori定律
為了減少頻繁項集的生成時間,我們應該盡早的消除一些完全不可能是頻繁項集的集合,Apriori的兩條定律就是干這事的。
Apriori定律1:如果一個集合是頻繁項集,則它的所有子集都是頻繁項集。舉例:假設一個集合{A,B}是頻繁項集,即A、B同時出現在一條記錄的次數大于等于最小支持度min_support,則它的子集{A},{B}出現次數必定大于等于min_support,即它的子集都是頻繁項集。
Apriori定律2:如果一個集合不是頻繁項集,則它的所有超集都不是頻繁項集。舉例:假設集合{A}不是頻繁項集,即A出現的次數小于min_support,則它的任何超集如{A,B}出現的次數必定小于min_support,因此其超集必定也不是頻繁項集。
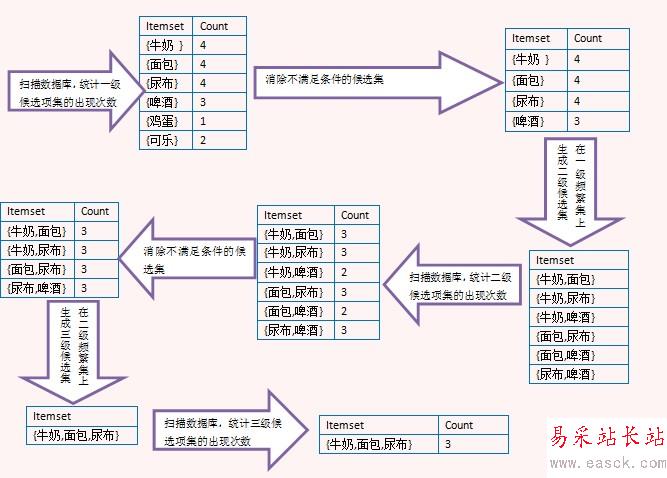
上面的圖演示了Apriori算法的過程,注意看由二級頻繁項集生成三級候選項集時,沒有{牛奶,面包,啤酒},那是因為{面包,啤酒}不是二級頻繁項集,這里利用了Apriori定理。最后生成三級頻繁項集后,沒有更高一級的候選項集,因此整個算法結束,{牛奶,面包,尿布}是最大頻繁子集。
Python實現代碼:
代碼如下:
Skip to content
Sign up Sign in This repository
Explore
Features
Enterprise
Blog
Star 0 Fork 0 taizilongxu/datamining
branch: master datamining / apriori / apriori.py
hackerxutaizilongxu 20 days ago backup
1 contributor
156 lines (140 sloc) 6.302 kb RawBlameHistory
新聞熱點






疑難解答













