在本文中,以'哈'來解釋作示例解釋所有的問題,“哈”的各種編碼如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以來,python中的中文編碼就是一個極為頭大的問題,經常拋出編碼轉換的異常,python中的str和unicode到底是一個什么東西呢?
在python中提到unicode,一般指的是unicode對象,例如'哈哈'的unicode對象為
u'/u54c8/u54c8'
而str,是一個字節數組,這個字節數組表示的是對unicode對象編碼(可以是utf-8、gbk、cp936、GB2312)后的存儲的格式。這里它僅僅是一個字節流,沒有其它的含義,如果你想使這個字節流顯示的內容有意義,就必須用正確的編碼格式,解碼顯示。
例如: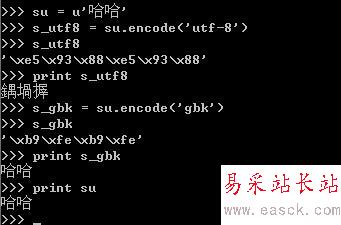
對于unicode對象哈哈進行編碼,編碼成一個utf-8編碼的str-s_utf8,s_utf8就是是一個字節數組,存放的就是'/xe5/x93/x88/xe5/x93/x88',但是這僅僅是一個字節數組,如果你想將它通過print語句輸出成哈哈,那你就失望了,為什么呢?
因為print語句它的實現是將要輸出的內容傳送了操作系統,操作系統會根據系統的編碼對輸入的字節流進行編碼,這就解釋了為什么utf-8格式的字符串“哈哈”,輸出的是“鍝堝搱”,因為 '/xe5/x93/x88/xe5/x93/x88'用GB2312去解釋,其顯示的出來就是“鍝堝搱”。這里再強調一下,str記錄的是字節數組,只是某種編碼的存儲格式,至于輸出到文件或是打印出來是什么格式,完全取決于其解碼的編碼將它解碼成什么樣子。
這里再對print進行一點補充說明:當將一個unicode對象傳給print時,在內部會將該unicode對象進行一次轉換,轉換成本地的默認編碼(這僅是個人猜測)
str和unicode對象的轉換,通過encode和decode實現,具體使用如下:
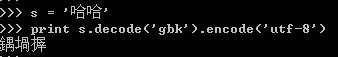
將GBK'哈哈'轉換成unicode,然后再轉換成UTF8
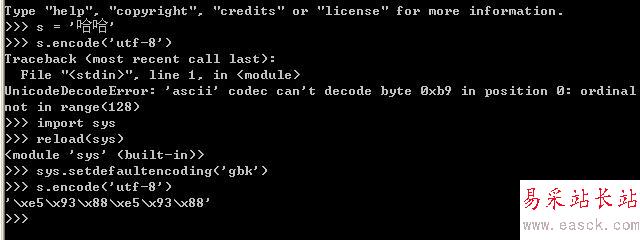
如上圖的演示代碼所示:
當把s(gbk字符串)直接編碼成utf-8的時候,將拋出異常,但是通過調用如下代碼:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
后就可以轉換成功,為什么呢?在python中str和unicode在編碼和解碼過程中,如果將一個str直接編碼成另一種編碼,會先把str解碼成unicode,采用的編碼為默認編碼,一般默認編碼是anscii,所以在上面示例代碼中第一次轉換的時候會出錯,當設定當前默認編碼為'gbk'后,就不會出錯了。
新聞熱點






疑難解答













