0x01
春節閑著沒事(是有多閑),就寫了個簡單的程序,來爬點笑話看,順帶記錄下寫程序的過程。第一次接觸爬蟲是看了這么一個帖子,一個逗逼,爬取煎蛋網上妹子的照片,簡直不要太方便。于是乎就自己照貓畫虎,抓了點圖片。
科技啟迪未來,身為一個程序員,怎么能干這種事呢,還是爬點笑話比較有益于身心健康。

0x02
在我們擼起袖子開始搞之前,先來普及點理論知識。
簡單地說,我們要把網頁上特定位置的內容,扒拉下來,具體怎么扒拉,我們得先分析這個網頁,看那塊內容是我們需要的。比如,這次爬取的是捧腹網上的笑話,打開 捧腹網段子頁我們可以看到一大堆笑話,我們的目的就是獲取這些內容。看完回來冷靜一下,你這樣一直笑,我們沒辦法寫代碼。在 chrome 中,我們打開 審查元素 然后一級一級的展開 HTML 標簽,或者點擊那個小鼠標,定位我們所需要的元素。
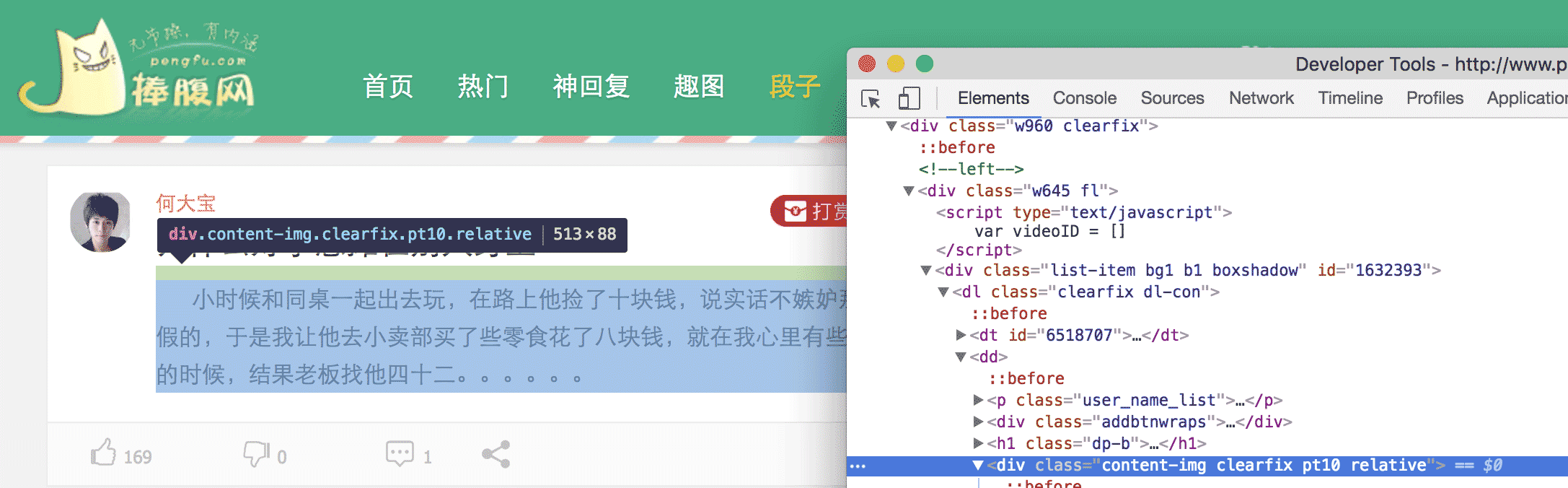
最后可以發現 <div> 中的內容就是我們所需要的笑話,在看第二條笑話,也是這樣。于是乎,我們就可以把這個網頁中所有的 <div> 找到,然后把里邊的內容提取出來,就完成了。
0x03
好了,現在我們知道我們的目的了,就可以擼起袖子開始干了。這里我用的 python3,關于 python2 和 python3 的選用,大家可以自行決定,功能都可以實現,只是有些許不同。但還是建議用 python3。
我們要扒拉下我們需要的內容,首先我們得把這個網頁扒拉下來,怎么扒拉呢,這里我們要用到一個庫,叫 urllib,我們用這個庫提供的方法,來獲取整個網頁。
首先,我們導入 urllib
代碼如下: import urllib.request as request
然后,我們就可以使用 request 來獲取網頁了,
代碼如下: def getHTML(url):
return request.urlopen(url).read()
人生苦短,我用 python,一行代碼,下載網頁,你說,還有什么理由不用 python。
下載完網頁后,我們就得解析這個網頁了來獲取我們所需要的元素。為了解析元素,我們需要使用另外一個工具,叫做 Beautiful Soup,使用它,可以快速解析 HTML 和 XML并獲取我們所需要的元素。
代碼如下: soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))
用 BeautifulSoup 來解析網頁也就一句話,但當你運行代碼的時候,會出現這么一個警告,提示要指定一個解析器,不然,可能會在其他平臺或者系統上報錯。
代碼如下:/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
新聞熱點






疑難解答













