1.設置Headers
有些網站不會同意程序直接用上面的方式進行訪問,如果識別有問題,那么站點根本不會響應,所以為了完全模擬瀏覽器的工作,我們需要設置一些Headers 的屬性。
首先,打開我們的瀏覽器,調試瀏覽器F12,我用的是Chrome,打開網絡監聽,示意如下,比如知乎,點登錄之后,我們會發現登陸之后界面都變化 了,出現一個新的界面,實質上這個頁面包含了許許多多的內容,這些內容也不是一次性就加載完成的,實質上是執行了好多次請求,一般是首先請求HTML文 件,然后加載JS,CSS 等等,經過多次請求之后,網頁的骨架和肌肉全了,整個網頁的效果也就出來了。
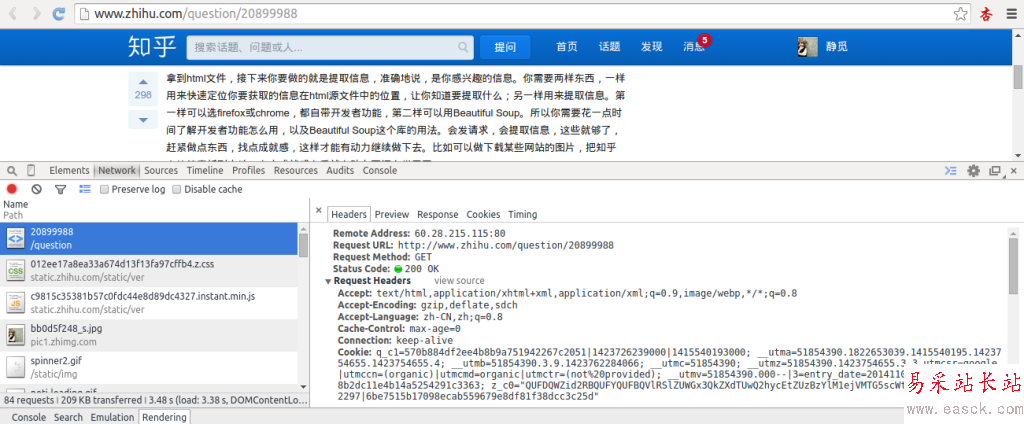
拆分這些請求,我們只看一第一個請求,你可以看到,有個Request URL,還有headers,下面便是response,圖片顯示得不全,小伙伴們可以親身實驗一下。那么這個頭中包含了許許多多是信息,有文件編碼啦,壓縮方式啦,請求的agent啦等等。
其中,agent就是請求的身份,如果沒有寫入請求身份,那么服務器不一定會響應,所以可以在headers中設置agent,例如下面的例子,這個例子只是說明了怎樣設置的headers,小伙伴們看一下設置格式就好。
import urllib import urllib2 url = 'http://www.server.com/login'user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' values = {'username' : 'cqc', 'password' : 'XXXX' } headers = { 'User-Agent' : user_agent } data = urllib.urlencode(values) request = urllib2.Request(url, data, headers) response = urllib2.urlopen(request) page = response.read()這樣,我們設置了一個headers,在構建request時傳入,在請求時,就加入了headers傳送,服務器若識別了是瀏覽器發來的請求,就會得到響應。
另外,我們還有對付”反盜鏈”的方式,對付防盜鏈,服務器會識別headers中的referer是不是它自己,如果不是,有的服務器不會響應,所以我們還可以在headers中加入referer
例如我們可以構建下面的headers
headers = { 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' , 'Referer':'http://www.zhihu.com/articles' }同上面的方法,在傳送請求時把headers傳入Request參數里,這樣就能應付防盜鏈了。
另外headers的一些屬性,下面的需要特別注意一下:
新聞熱點






疑難解答













