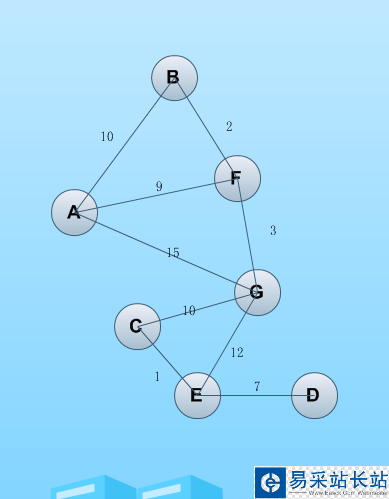
一心想學習算法,很少去真正靜下心來去研究,前幾天趁著周末去了解了最短路徑的資料,用python寫了一個最短路徑算法。算法是基于帶權無向圖去尋找兩個點之間的最短路徑,數據存儲用鄰接矩陣記錄。首先畫出一幅無向圖如下,標出各個節點之間的權值。
其中對應索引:
A ——> 0
B——> 1
C——> 2
D——>3
E——> 4
F——> 5
G——> 6
鄰接矩陣表示無向圖:

算法思想是通過Dijkstra算法結合自身想法實現的。大致思路是:從起始點開始,搜索周圍的路徑,記錄每個點到起始點的權值存到已標記權值節點字典A,將起始點存入已遍歷列表B,然后再遍歷已標記權值節點字典A,搜索節點周圍的路徑,如果周圍節點存在于表B,比較累加權值,新權值小于已有權值則更新權值和來源節點,否則什么都不做;如果不存在與表B,則添加節點和權值和來源節點到表A,直到搜索到終點則結束。
這時最短路徑存在于表A中,得到終點的權值和來源路徑,向上遞推到起始點,即可得到最短路徑,下面是代碼:
# -*-coding:utf-8 -*-class DijkstraExtendPath(): def __init__(self, node_map): self.node_map = node_map self.node_length = len(node_map) self.used_node_list = [] self.collected_node_dict = {} def __call__(self, from_node, to_node): self.from_node = from_node self.to_node = to_node self._init_dijkstra() return self._format_path() def _init_dijkstra(self): self.used_node_list.append(self.from_node) self.collected_node_dict[self.from_node] = [0, -1] for index1, node1 in enumerate(self.node_map[self.from_node]): if node1: self.collected_node_dict[index1] = [node1, self.from_node] self._foreach_dijkstra() def _foreach_dijkstra(self): if len(self.used_node_list) == self.node_length - 1: return for key, val in self.collected_node_dict.items(): # 遍歷已有權值節點 if key not in self.used_node_list and key != to_node: self.used_node_list.append(key) else: continue for index1, node1 in enumerate(self.node_map[key]): # 對節點進行遍歷 # 如果節點在權值節點中并且權值大于新權值 if node1 and index1 in self.collected_node_dict and self.collected_node_dict[index1][0] > node1 + val[0]: self.collected_node_dict[index1][0] = node1 + val[0] # 更新權值 self.collected_node_dict[index1][1] = key elif node1 and index1 not in self.collected_node_dict: self.collected_node_dict[index1] = [node1 + val[0], key] self._foreach_dijkstra() def _format_path(self): node_list = [] temp_node = self.to_node node_list.append((temp_node, self.collected_node_dict[temp_node][0])) while self.collected_node_dict[temp_node][1] != -1: temp_node = self.collected_node_dict[temp_node][1] node_list.append((temp_node, self.collected_node_dict[temp_node][0])) node_list.reverse() return node_listdef set_node_map(node_map, node, node_list): for x, y, val in node_list: node_map[node.index(x)][node.index(y)] = node_map[node.index(y)][node.index(x)] = valif __name__ == "__main__": node = ['A', 'B', 'C', 'D', 'E', 'F', 'G'] node_list = [('A', 'F', 9), ('A', 'B', 10), ('A', 'G', 15), ('B', 'F', 2), ('G', 'F', 3), ('G', 'E', 12), ('G', 'C', 10), ('C', 'E', 1), ('E', 'D', 7)] node_map = [[0 for val in xrange(len(node))] for val in xrange(len(node))] set_node_map(node_map, node, node_list) # A -->; D from_node = node.index('A') to_node = node.index('D') dijkstrapath = DijkstraPath(node_map) path = dijkstrapath(from_node, to_node) print path
新聞熱點






疑難解答













