前言
Pandas是Python當(dāng)中重要的數(shù)據(jù)分析工具,利用Pandas進(jìn)行數(shù)據(jù)分析時(shí),確保使用正確的數(shù)據(jù)類型是非常重要的,否則可能會導(dǎo)致一些不可預(yù)知的錯(cuò)誤發(fā)生。
Pandas 的數(shù)據(jù)類型:數(shù)據(jù)類型本質(zhì)上是編程語言用來理解如何存儲和操作數(shù)據(jù)的內(nèi)部結(jié)構(gòu)。例如,一個(gè)程序需要理解你可以將兩個(gè)數(shù)字加起來,比如 5 + 10 得到 15。或者,如果是兩個(gè)字符串,比如「cat」和「hat」,你可以將它們連接(加)起來得到「cathat」。尚學(xué)堂•百戰(zhàn)程序員陳老師指出有關(guān) Pandas 數(shù)據(jù)類型的一個(gè)可能令人困惑的地方是,Pandas、Python 和 numpy 的數(shù)據(jù)類型之間有一些重疊。
大多數(shù)情況下,你不必?fù)?dān)心是否應(yīng)該明確地將熊貓類型強(qiáng)制轉(zhuǎn)換為對應(yīng)的 NumPy 類型。一般來說使用 Pandas 的默認(rèn) int64 和 float64 就可以。我列出此表的唯一原因是,有時(shí)你可能會在代碼行間或自己的分析過程中看到 Numpy 的類型。
數(shù)據(jù)類型是在你遇到錯(cuò)誤或意外結(jié)果之前并不會關(guān)心的事情之一。不過當(dāng)你將新數(shù)據(jù)加載到 Pandas 進(jìn)行進(jìn)一步分析時(shí),這也是你應(yīng)該檢查的第一件事情。
筆者使用Pandas已經(jīng)有一段時(shí)間了,但是還是會在一些小問題上犯錯(cuò)誤,追根溯源發(fā)現(xiàn)在對數(shù)據(jù)進(jìn)行操作時(shí)某些特征列并不是Pandas所能處理的類型。因此本文將討論一些小技巧如何將Python的基本數(shù)據(jù)類型轉(zhuǎn)化為Pandas所能處理的數(shù)據(jù)類型。
Pandas、Numpy、Python各自支持的數(shù)據(jù)類型
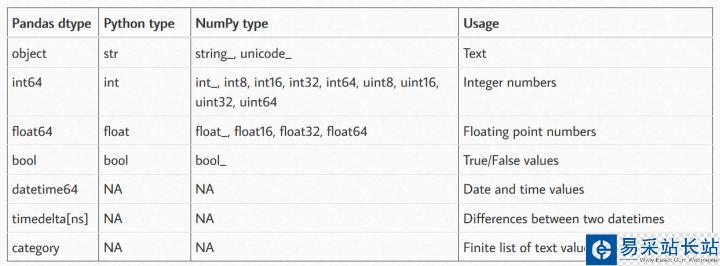
從上述表格中可以看出Pandas支持的數(shù)據(jù)類型最為豐富,在某種情形下Numpy的數(shù)據(jù)類型可以和Pandas的數(shù)據(jù)類型相互轉(zhuǎn)化,畢竟Pandas庫是在Numpy的基礎(chǔ)之上開發(fā)的的。
引入實(shí)際數(shù)據(jù)進(jìn)行分析
數(shù)據(jù)類型是你平常可能不太關(guān)心,直到得到了錯(cuò)誤的結(jié)果才映像深刻的東西,因此在這里引入一個(gè)實(shí)際數(shù)據(jù)分析的例子來加深理解。
import numpy as npimport pandas as pddata = pd.read_csv('data.csv', encoding='gbk') #因?yàn)閿?shù)據(jù)中含有中文數(shù)據(jù)data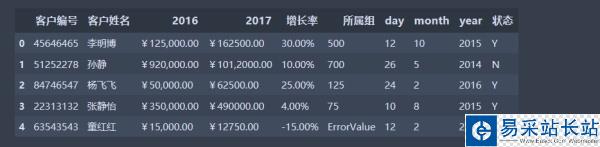
數(shù)據(jù)加載完畢,如果現(xiàn)在想要在該數(shù)據(jù)上進(jìn)行一些操作,比如把數(shù)據(jù)列2016、2017對應(yīng)項(xiàng)相加。
data['2016'] + data['2017'] #想當(dāng)然的做法
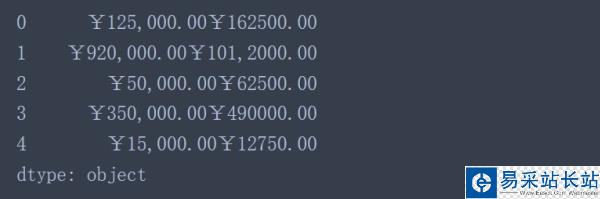
從結(jié)果來看并沒有像想象中那樣數(shù)值對應(yīng)相加,這是因?yàn)樵赑andas中object類型相加等價(jià)于Python中的字符串相加。
data.info() #在對數(shù)據(jù)進(jìn)行處理之前應(yīng)該先查看加載數(shù)據(jù)的相關(guān)信息
新聞熱點(diǎn)






疑難解答
圖片精選













