本文實例講述了Python實現爬取百度貼吧帖子所有樓層圖片的爬蟲。分享給大家供大家參考,具體如下:
下載百度貼吧帖子圖片,好好看
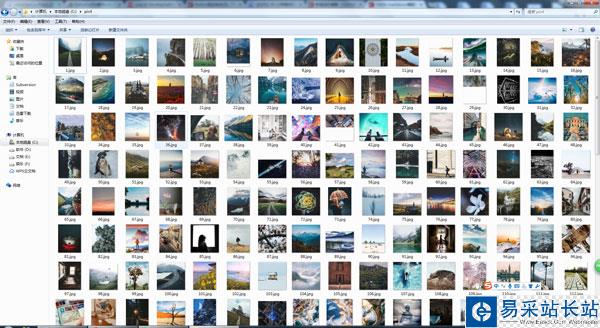
python2.7版本:
#coding=utf-8import reimport requestsimport urllibfrom bs4 import BeautifulSoupimport timetime1=time.time()def getHtml(url): page = requests.get(url) html =page.text return htmldef getImg(html): soup = BeautifulSoup(html, 'html.parser') img_info = soup.find_all('img', class_='BDE_Image') global index for index,img in enumerate(img_info,index+1): print ("正在下載第{}張圖片".format(index)) urllib.urlretrieve(img.get("src"),'C:/pic4/%s.jpg' % index)def getMaxPage(url): html = getHtml(url) reg = re.compile(r'max-page="(/d+)"') page = re.findall(reg,html) page = int(page[0]) return pageif __name__=='__main__': url = "https://tieba.baidu.com/p/5113603072" page = getMaxPage(url) index = 0 for i in range(1,page): url = "%s%s" % ("https://tieba.baidu.com/p/5113603072?pn=",str(i)) html = getHtml(url) getImg(html) print ("OK!All DownLoad!") time2=time.time() print u'總共耗時:' + str(time2 - time1) + 's'PS:這里再為大家提供2款非常方便的正則表達式工具供大家參考使用:
JavaScript正則表達式在線測試工具:
http://tools.jb51.net/regex/javascript
正則表達式在線生成工具:
http://tools.jb51.net/regex/create_reg
更多關于Python相關內容可查看本站專題:《Python Socket編程技巧總結》、《Python正則表達式用法總結》、《Python數據結構與算法教程》、《Python函數使用技巧總結》、《Python字符串操作技巧匯總》、《Python入門與進階經典教程》及《Python文件與目錄操作技巧匯總》
希望本文所述對大家Python程序設計有所幫助。
新聞熱點






疑難解答













