前言: 在進行數據處理的時候,我們經常會用到 pandas 。但是 pandas 本身好像并沒有提供多進程的機制。本文將介紹如何來自己實現 pandas (apply 函數)的多進程執行。其中,我們主要借助 joblib 庫,這個庫為python 提供了一個非常簡潔方便的多進程實現方法。
所以,本文將按照下面的安排展開,前面可能比較啰嗦,若只是想知道怎么用可直接看第三部分:
- 首先簡單介紹 pandas 中的分組聚合操作 groupby。
- 然后簡單介紹 joblib 的使用方法。
- 最后,通過一個去停用詞的實驗詳細介紹如何實現 pandas 中 apply 函數多進程執行。
注意:本文說的都是多進程而不是多線程。
1. DataFrame.groupby 分組聚合操作
# groupby 操作df1 = pd.DataFrame({'a':[1,2,1,2,1,2], 'b':[3,3,3,4,4,4], 'data':[12,13,11,8,10,3]})df1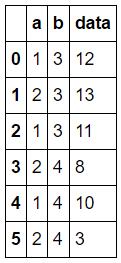
按照某列分組
grouped = df1.groupby('b')# 按照 'b' 這列分組了,name 為 'b' 的 key 值,group 為對應的df_groupfor name, group in grouped: print name, '->' print group3 -> a b data0 1 3 121 2 3 132 1 3 114 -> a b data3 2 4 84 1 4 105 2 4 3
按照多列分組
grouped = df1.groupby(['a','b'])# 按照 'b' 這列分組了,name 為 'b' 的 key 值,group 為對應的df_groupfor name, group in grouped: print name, '->' print group
(1, 3) -> a b data0 1 3 122 1 3 11(1, 4) -> a b data4 1 4 10(2, 3) -> a b data1 2 3 13(2, 4) -> a b data3 2 4 85 2 4 3
若 df.index 為[1,2,3…]這樣一個 list, 那么按照 df.index分組,其實就是每組就是一行,在后面去停用詞實驗中,我們就用這個方法把 df_all 處理成每行為一個元素的 list, 再用多進程處理這個 list。
grouped = df1.groupby(df1.index)# 按照 index 分組,其實每行就是一個組了print len(grouped), type(grouped)for name, group in grouped: print name, '->' print group
6 <class 'pandas.core.groupby.DataFrameGroupBy'>0 -> a b data0 1 3 121 -> a b data1 2 3 132 -> a b data2 1 3 113 -> a b data3 2 4 84 -> a b data4 1 4 105 -> a b data5 2 4 3
2. joblib 用法
refer: https://pypi.python.org/pypi/joblib
# 1. Embarrassingly parallel helper: to make it easy to write readable parallel code and debug it quickly:from joblib import Parallel, delayedfrom math import sqrt
處理小任務的時候,多進程并沒有體現出優勢。
%time result1 = Parallel(n_jobs=1)(delayed(sqrt)(i**2) for i in range(10000))%time result2 = Parallel(n_jobs=8)(delayed(sqrt)(i**2) for i in range(10000))
新聞熱點






疑難解答













