概述
這是一個簡單的python爬蟲程序,僅用作技術學習與交流,主要是通過一個簡單的實際案例來對網絡爬蟲有個基礎的認識。
什么是網絡爬蟲
簡單的講,網絡爬蟲就是模擬人訪問web站點的行為來獲取有價值的數據。專業的解釋:百度百科
分析爬蟲需求
確定目標
爬取豆瓣熱度在Top100以內的電影的一些信息,包括電影的名稱、豆瓣評分、導演、編劇、主演、類型、制片國家/地區、語言、上映日期、片長、IMDb鏈接等信息。
分析目標
1.借助工具分析目標網頁
首先,我們打開豆瓣電影·熱門電影,會發現頁面總共20部電影,但當查看頁面源代碼當時候,在源代碼中根本找不到這些電影當信息。這是為什么呢?原來豆瓣在這里是通過ajax技術獲取電影信息,再動態的將數據加載到頁面中的。這就需要借助Chrome的開發者工具,先找到獲取電影信息的API。
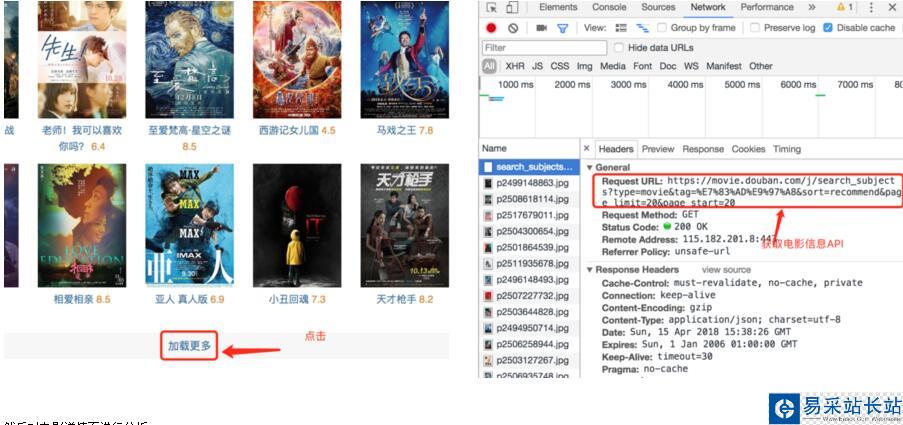
然后對電影詳情頁進行分析
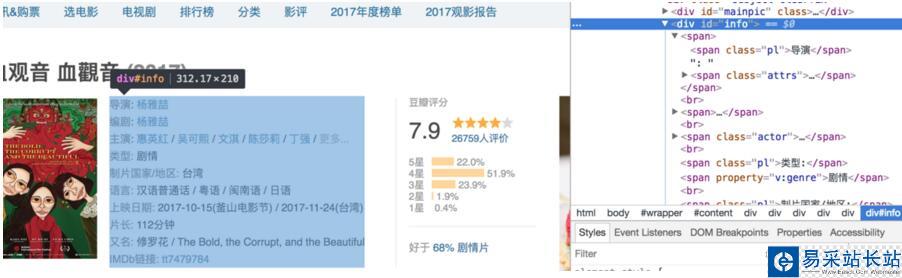
思路分析
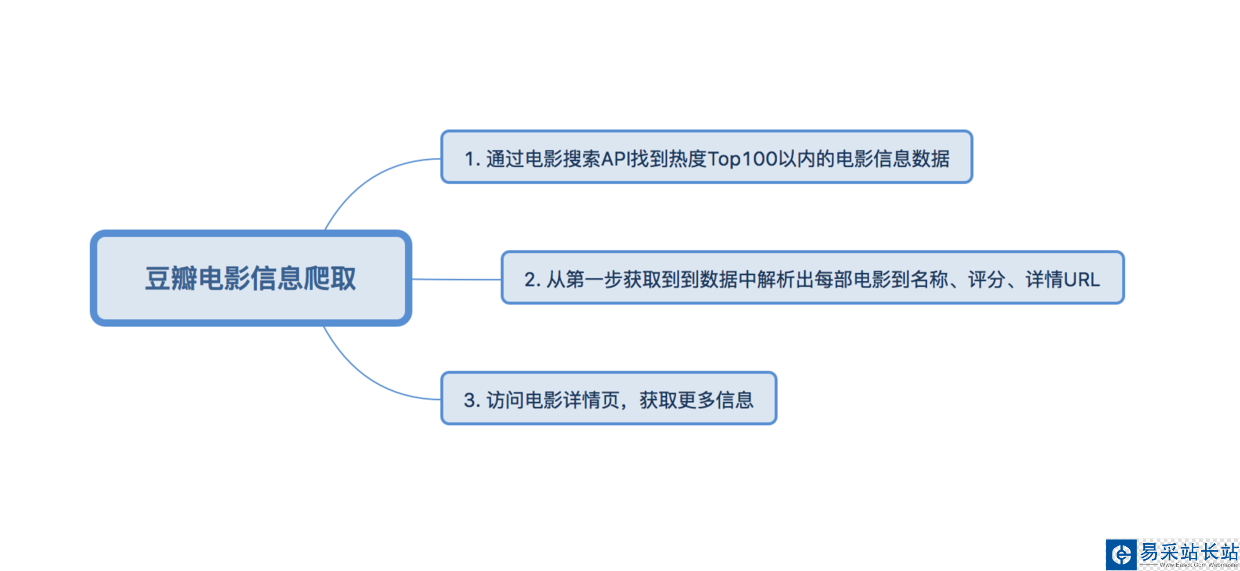
具體實現
開發環境
python3.6
pycharm
主要依賴庫
urllib -- 基礎性的網絡相關操作
lxml -- 通過xpath語法解析HTML頁面
json -- 對通過API獲取的JSON數據進行操作
re -- 正則操作
代碼實現
from urllib import requestfrom lxml import etreeimport jsonimport reimport ssl# 全局取消證書驗證ssl._create_default_https_context = ssl._create_unverified_contextdef get_headers(): """ 返回請求頭信息 :return: """ headers = { 'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/65.0.3325.181 Safari/537.36" } return headersdef get_url_content(url): """ 獲取指定url的請求內容 :param url: :return: """ content = '' headers = get_headers() res = request.Request(url, headers=headers) try: resp = request.urlopen(res, timeout=10) content = resp.read().decode('utf-8') except Exception as e: print('exception: %s' % e) return contentdef parse_content(content): """ 解析網頁 :param content: :return: """ movie = {} html = etree.HTML(content) try: info = html.xpath("http://div[@id='info']")[0] movie['director'] = info.xpath("./span[1]/span[2]/a/text()")[0] movie['screenwriter'] = info.xpath("./span[2]/span[2]/a/text()")[0] movie['actors'] = '/'.join(info.xpath("./span[3]/span[2]/a/text()")) movie['type'] = '/'.join(info.xpath("./span[@property='v:genre']/" "text()")) movie['initialReleaseDate'] = '/'./ join(info.xpath(".//span[@property='v:initialReleaseDate']/text()")) movie['runtime'] = / info.xpath(".//span[@property='v:runtime']/text()")[0] def str_strip(s): return s.strip() def re_parse(key, regex): ret = re.search(regex, content) movie[key] = str_strip(ret[1]) if ret else '' re_parse('region', r'<span class="pl">制片國家/地區:</span>(.*?)<br/>') re_parse('language', r'<span class="pl">語言:</span>(.*?)<br/>') re_parse('imdb', r'<span class="pl">IMDb鏈接:</span> <a href="(.*?)" rel="external nofollow" ' r'target="_blank" >') except Exception as e: print('解析異常: %s' % e) return moviedef spider(): """ 爬取豆瓣前100部熱門電影 :return: """ recommend_moives = [] movie_api = 'https://movie.douban.com/j/search_subjects?' / 'type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend' / '&page_limit=100&page_start=0' content = get_url_content(movie_api) json_dict = json.loads(content) subjects = json_dict['subjects'] for subject in subjects: content = get_url_content(subject['url']) movie = parse_content(content) movie['title'] = subject['title'] movie['rate'] = subject['rate'] recommend_moives.append(movie) print(len(recommend_moives)) print(recommend_moives)if __name__ == '__main__': spider()
新聞熱點






疑難解答













