#寫在前面,這個程序我已經弄出來了,但是因為黃牛泛濫以及懶人太多,整個程序的代碼就不貼出來了,這里純粹就是技術交流。
只做技術交流、、、、、

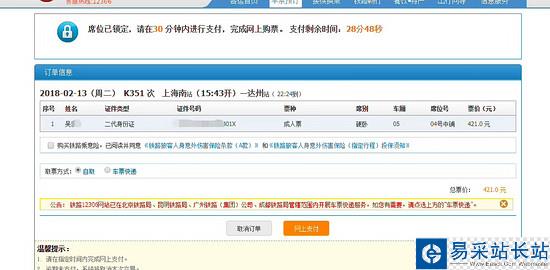
嗯,程序結束后,自己還是得手動付款。
廢話不多說,下面就直接開始技術主要部分闡述。
先講理論部分:首先我們需要代碼實現一個瀏覽器功能,那么模塊基本上可以確定urllib.parse、urllib.request,這兩個包都是和網址有關的模塊,那么咱們去登錄一個網址,特別是有驗證碼這些的網址,我們登錄進去是不是就行了?答案是對的,但是我們用代碼實現的話,這個網址可能每次都有可能被代碼去請求,那么服務器怎么知道我們是一個人,而不是多個瀏覽器不同的用戶呢?
此時cookie就非常重要了,在代碼中設置好cookie,那么對方服務器自然就知道我們是一個人,比較服務器都是這么區分的。python3中 cookie這個功能是封裝在http.cookiejar這個模塊之內。好了,代碼如下:
# coding=utf-8# author: Jason# time:2018/1/16 20:00:00#version:1.0import urllib.request as ulimport urllib.parse as uzimport http.cookiejar as cookielibfrom json import loadsc=cookielib.LWPCookieJar()#先把cookie對象存儲為cookiejar的對象cookie = ul.HTTPCookieProcessor(c)#把cookiejar對象轉換為一個handleopener = ul.build_opener(cookie)#建立一個模擬瀏覽器,需要handle作為參數ul.install_opener(opener)#安裝一個全局模擬瀏覽器,代表無論怎么訪問都是一個瀏覽器操作而不是分開獲取驗證碼等msg
好了,如此一來,我們代碼的初步實現已經完成,接下來就是進入網絡分析部分
首先可以使用google瀏覽器或者搜狗瀏覽器(本人用的搜狗),打開F12,也就是開發者模式,登錄12306的登錄地址 https://kyfw.12306.cn/otn/login/init
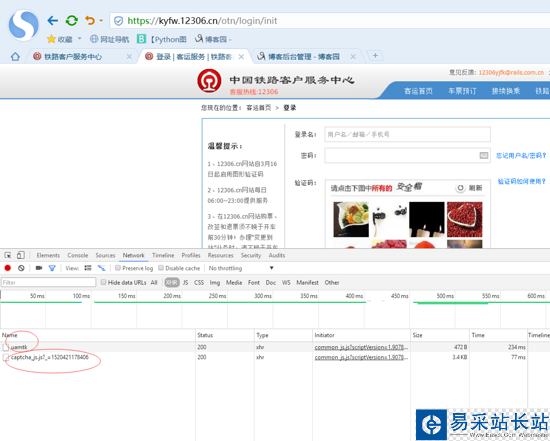
兩個紅圈中第二個是驗證碼來源,此時我們只需要記錄這個網頁(點進去)的詳細情況,寫入代碼當中,python3中urllib.request這個模塊打開既可

如此便是驗證碼來源,那么如何用代碼捕捉呢?首先我們可以先亂輸入密碼,亂點驗證碼,然后我們直接點擊登錄
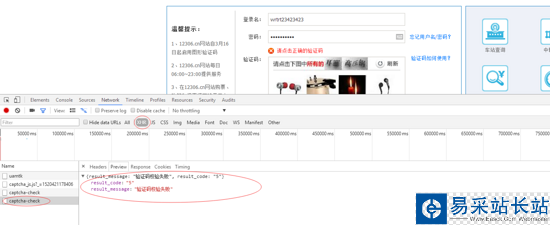
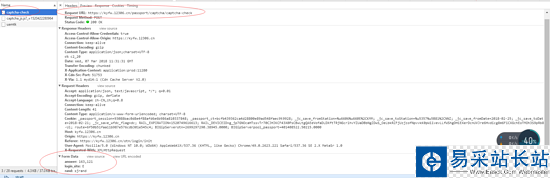
多了一個很奇妙的東西,此時,這里就是驗證碼驗證的網址,那么我們是不是應該記錄下來呢?很簡單,到Headers里面就全都看得到了
新聞熱點






疑難解答













