使用正則表達(dá)式的幾個(gè)步驟:
1、用import re 導(dǎo)入正則表達(dá)式模塊;
2、用re.compile()函數(shù)創(chuàng)建一個(gè)Regex對(duì)象;
3、用Regex對(duì)象的search()或findall()方法,傳入想要查找的字符串,返回一個(gè)Match對(duì)象;
4、調(diào)用Match對(duì)象的group()方法,返回匹配到的字符串。
在交互式環(huán)境中簡(jiǎn)單嘗試一下,查詢字符串中的固話:
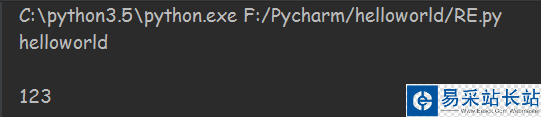
import re text = '小明家的固話是0755-123456,而小麗家的固話時(shí)0789-654321,小王家的電話是123456789'#用于檢測(cè)的字符串 ph_re = re.compile(r'/d{4}?-/d+') #創(chuàng)建Regex對(duì)象,匹配幾種電話的方式,/d表示0-9的數(shù)字,{4}表示前面的匹配4次,?表示可選,+表示出現(xiàn)1次或多次。 matchs1 = ph_re.findall(text) #findall()表示查找所有匹配項(xiàng),返回一個(gè)字符串 matchs2 = ph_re.search(text)#search(),查找第一次匹配的文本,返回一個(gè)對(duì)象。 print(matchs1) print(matchs2) matchs2.group()返回的結(jié)果,是這樣的:
findall()方法返回的是一個(gè)字符串,可以直接打印出來。而search()方法返回的是一個(gè)對(duì)象,所以打印出來的是是如圖的第二行。
調(diào)用group(),對(duì)象返回匹配的結(jié)果。
最后,小王的電話之所以沒有匹配到,是因?yàn)?-'沒有進(jìn)行可選即在其后加上‘?'。
下面進(jìn)行一個(gè)小的實(shí)驗(yàn),獲取某個(gè)網(wǎng)頁中所有的http/https網(wǎng)址,并計(jì)算有多少個(gè)。
首先是獲取HTML文件。這里要用到requests模塊。
# -*- coding: utf-8 -*- import requests import re def get_html(url): res = requests.get(url) res.encoding = 'utf-8' html = res.text return html
這里get_html函數(shù)返回的,其實(shí)就類似上面例子中的text,用來匹配的文本。
然后,創(chuàng)建正則表達(dá)式:
def get_addr(response): addr_regex = re.compile(r'''( (http://|https://)? #http/https (www)? (/.[a-z1-9A-Z]+) (/.com|/.cn) )''',re.VERBOSE)#匹配網(wǎng)址, matchs = [] for groups in addr_regex.findall(response): matchs.append(groups[0]) if len(matchs) == 0: print('沒有網(wǎng)址') return matchs這里向re.compile(),傳入變量re.VERBOSE,作為第二個(gè)參數(shù),可以將正則表達(dá)式放在多行,并進(jìn)行注釋,如上。
返回一個(gè)matchs列表對(duì)象。
再來個(gè)啟動(dòng)函數(shù)。
def start(): url = 'http://news.163.com/18/0127/18/D966K4CO0001899N.html' a = get_html(url) b = get_addr(a) print('/n'.join(b)) print(str(len(b))) print('ok')if __name__ == '__main__': start()這里傳入的url是我隨意找的一個(gè)新聞鏈接。
然后調(diào)用get_html()和get_addr(),就得到了想要的東西。str(len(b)),為統(tǒng)計(jì)的數(shù)量。
測(cè)試的結(jié)果是類似這樣的:
這里似乎獲取一些URL,沒什么卵用。。。但是,如果結(jié)合前面的查詢新聞列表的方式,獲取批量url,
新聞熱點(diǎn)






疑難解答
圖片精選