收集所有外部鏈接的網站爬蟲程序流程圖
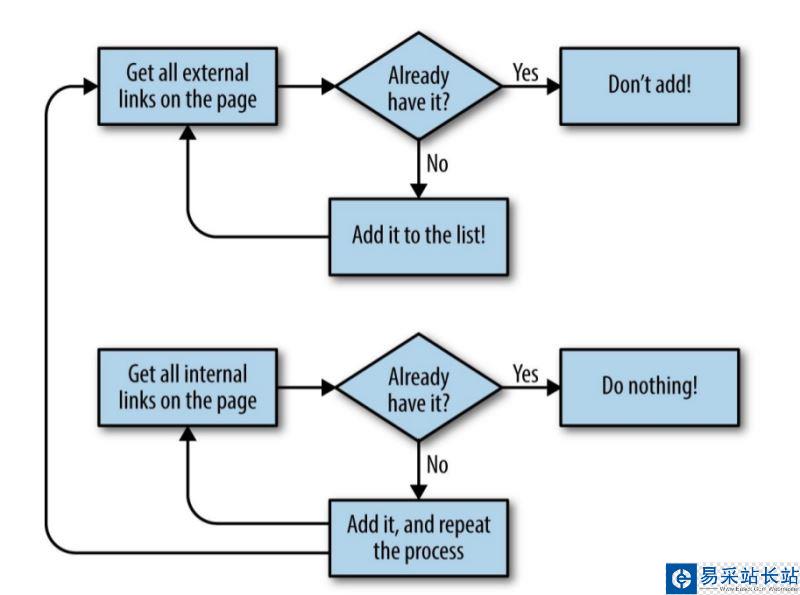
下例是爬取本站python繪制條形圖方法代碼詳解的實例,大家可以參考下。
完整代碼:
#! /usr/bin/env python#coding=utf-8import urllib2from bs4 import BeautifulSoupimport reimport datetimeimport randompages=set()random.seed(datetime.datetime.now())#Retrieves a list of all Internal links found on a pagedef getInternalLinks(bsObj, includeUrl): internalLinks = [] #Finds all links that begin with a "/" for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")): if link.attrs['href'] is not None: if link.attrs['href'] not in internalLinks: internalLinks.append(link.attrs['href']) return internalLinks#Retrieves a list of all external links found on a pagedef getExternalLinks(bsObj, excludeUrl): externalLinks = [] #Finds all links that start with "http" or "www" that do #not contain the current URL for link in bsObj.findAll("a", href=re.compile("^(http|www)((?!"+excludeUrl+").)*$")): if link.attrs['href'] is not None: if link.attrs['href'] not in externalLinks: externalLinks.append(link.attrs['href']) return externalLinksdef splitAddress(address): addressParts = address.replace("http://", "").split("/") return addressPartsdef getRandomExternalLink(startingPage): html= urllib2.urlopen(startingPage) bsObj = BeautifulSoup(html) externalLinks = getExternalLinks(bsObj, splitAddress(startingPage)[0]) if len(externalLinks) == 0: internalLinks = getInternalLinks(startingPage) return internalLinks[random.randint(0, len(internalLinks)-1)] else: return externalLinks[random.randint(0, len(externalLinks)-1)]def followExternalOnly(startingSite): externalLink=getRandomExternalLink("http://www.jb51.net/article/130968.htm") print("Random external link is: "+externalLink) followExternalOnly(externalLink)#Collects a list of all external URLs found on the siteallExtLinks=set()allIntLinks=set()def getAllExternalLinks(siteUrl): html=urllib2.urlopen(siteUrl) bsObj=BeautifulSoup(html) internalLinks = getInternalLinks(bsObj,splitAddress(siteUrl)[0]) externalLinks = getExternalLinks(bsObj,splitAddress(siteUrl)[0]) for link in externalLinks: if link not in allExtLinks: allExtLinks.add(link) print(link) for link in internalLinks: if link not in allIntLinks: print("About to get link:"+link) allIntLinks.add(link) getAllExternalLinks(link)getAllExternalLinks("http://www.jb51.net/article/130968.htm")
新聞熱點






疑難解答













