正文
本文簡要介紹Python自然語言處理(NLP),使用Python的NLTK庫。NLTK是Python的自然語言處理工具包,在NLP領(lǐng)域中,最常使用的一個(gè)Python庫。
什么是NLP?
簡單來說,自然語言處理(NLP)就是開發(fā)能夠理解人類語言的應(yīng)用程序或服務(wù)。
這里討論一些自然語言處理(NLP)的實(shí)際應(yīng)用例子,如語音識(shí)別、語音翻譯、理解完整的句子、理解匹配詞的同義詞,以及生成語法正確完整句子和段落。
這并不是NLP能做的所有事情。
NLP實(shí)現(xiàn)
搜索引擎: 比如谷歌,Yahoo等。谷歌搜索引擎知道你是一個(gè)技術(shù)人員,所以它顯示與技術(shù)相關(guān)的結(jié)果;
社交網(wǎng)站推送:比如Facebook News Feed。如果News Feed算法知道你的興趣是自然語言處理,就會(huì)顯示相關(guān)的廣告和帖子。
語音引擎:比如Apple的Siri。
垃圾郵件過濾:如谷歌垃圾郵件過濾器。和普通垃圾郵件過濾不同,它通過了解郵件內(nèi)容里面的的深層意義,來判斷是不是垃圾郵件。
NLP庫
下面是一些開源的自然語言處理庫(NLP):
其中自然語言工具包(NLTK)是最受歡迎的自然語言處理庫(NLP),它是用Python編寫的,而且背后有非常強(qiáng)大的社區(qū)支持。
NLTK也很容易上手,實(shí)際上,它是最簡單的自然語言處理(NLP)庫。
在這個(gè)NLP教程中,我們將使用Python NLTK庫。
安裝 NLTK
如果您使用的是Windows/Linux/Mac,您可以使用pip安裝NLTK:
pip install nltk
打開python終端導(dǎo)入NLTK檢查NLTK是否正確安裝:
import nltk
如果一切順利,這意味著您已經(jīng)成功地安裝了NLTK庫。首次安裝了NLTK,需要通過運(yùn)行以下代碼來安裝NLTK擴(kuò)展包:
import nltknltk.download()
這將彈出NLTK 下載窗口來選擇需要安裝哪些包:
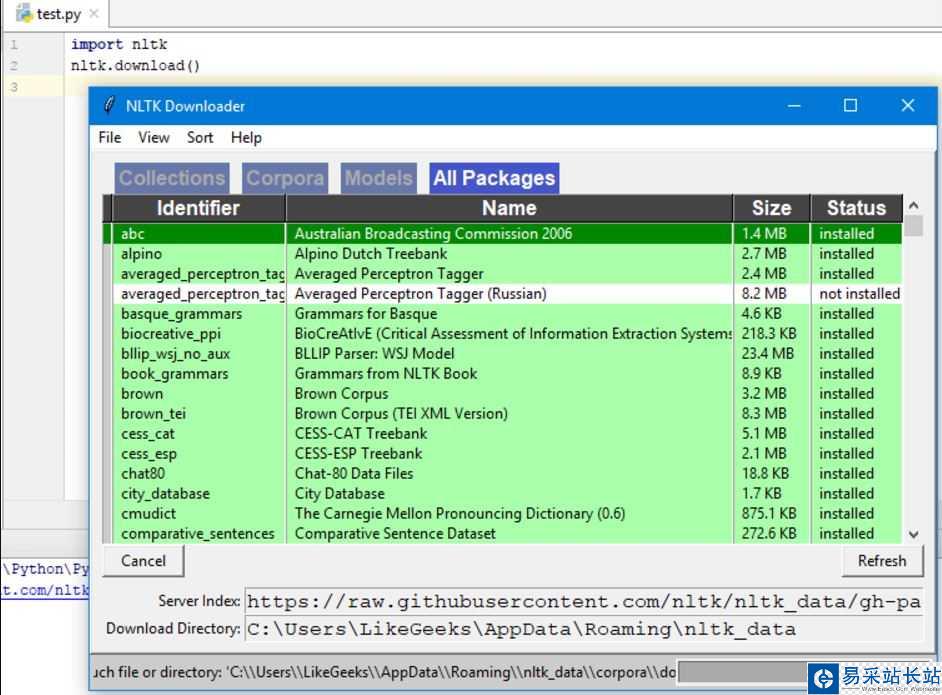
您可以安裝所有的包,因?yàn)樗鼈兊拇笮《己苄。詻]有什么問題。
使用Python Tokenize文本
首先,我們將抓取一個(gè)web頁面內(nèi)容,然后分析文本了解頁面的內(nèi)容。
我們將使用urllib模塊來抓取web頁面:
import urllib.requestresponse = urllib.request.urlopen('http://php.net/')html = response.read()print (html)從打印結(jié)果中可以看到,結(jié)果包含許多需要清理的HTML標(biāo)簽。
然后BeautifulSoup模塊來清洗這樣的文字:
from bs4 import BeautifulSoupimport urllib.requestresponse = urllib.request.urlopen('http://php.net/')html = response.read()soup = BeautifulSoup(html,"html5lib")# 這需要安裝html5lib模塊text = soup.get_text(strip=True)print (text)
新聞熱點(diǎn)






疑難解答
圖片精選













