上篇博客轉載了關于感知器的用法,遂這篇做個大概總結,并實現一個簡單的感知器,也為了加深自己的理解。
感知器是最簡單的神經網絡,只有一層。感知器是模擬生物神經元行為的機器。感知器的模型如下:
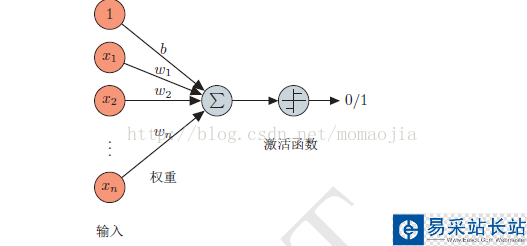
給定一個n維的輸入 ,其中w和b是參數,w為權重,每一個輸入對應一個權值,b為偏置項,需要從數據中訓練得到。
激活函數 感知器的激活函數可以有很多選擇,比如我們可以選擇下面這個階躍函數f來作為激活函數:
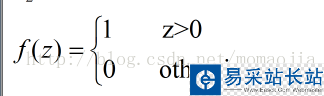
輸出為:

事實上感知器可以擬合任何線性函數,任何線性分類或線性回歸的問題都可以用感知器來解決。但是感知器不能實現異或運算,當然所有的線性分類器都不可能實現異或操作。
所謂異或操作:
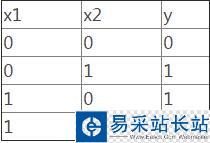
二維分布圖為:
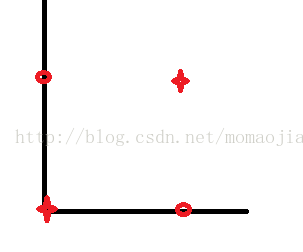
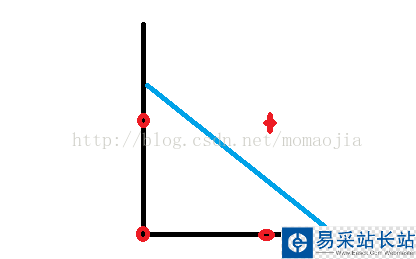
對于上圖,我們找不到一條直線可以將0,1類分開。對于and操作,感知器可以實現,我們可以找到一條直線把其分為兩部分。。
對于and操作:
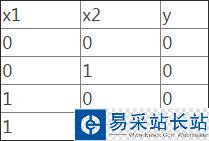
對應的二維分布圖為:
感知器的訓練
首先將權重w和 偏置b隨機初始化為一個很小的數,然后在訓練中不斷更新w和b的值。
1.將權重初始化為 0 或一個很小的隨機數
2.對于每個訓練樣本 x(i) 執行下列步驟:
計算輸出值 y^.
更新權重

其中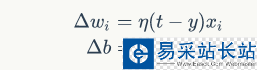
下面用感知器實現and操作,具體代碼如下:
# -*- coding: utf-8 -*- # python 3.4 import numpy as np from random import choice from sklearn import cross_validation from sklearn.linear_model import LogisticRegression ''''' 1.將權重初始化為 0 或一個很小的隨機數 2.對于每個訓練樣本 x(i) 執行下列步驟: 計算輸出值 y^. 更新權重 ''' def load_data(): input_data=[[1,1], [0,0], [1,0], [0,1]] labels=[1,0,0,0] return input_data,labels def train_pre(input_data,y,iteration,rate): #=========================== ''''' 參數: input_data:輸入數據 y:標簽列表 iteration:訓練輪數 rate:學習率 ''' #============================ unit_step = lambda x: 0 if x < 0 else 1 w=np.random.rand(len(input_data[0]))#隨機生成[0,1)之間,作為初始化w bias=0.0#偏置 for i in range(iteration): samples= zip(input_data,y) for (input_i,label) in samples:#對每一組樣本 #計算f(w*xi+b),此時x有兩個 result=input_i*w+bias result=float(sum(result)) y_pred=float(unit_step(result))#計算輸出值 y^ w=w+rate*(label-y_pred)*np.array(input_i)#更新權重 bias=rate*(label-y_pred)#更新bias return w,bias def predict(input_i,w,b): unit_step = lambda x: 0 if x < 0 else 1#定義激活函數 result=result=result=input_i*w+b result=sum(result) y_pred=float(unit_step(result)) print(y_pred) if __name__=='__main__': input_data,y=load_data() w,b=train_pre(input_data,y,20,0.01) predict([1,1],w,b)
新聞熱點






疑難解答













