1.反變換法
設需產生分布函數為F(x)的連續隨機數X。若已有[0,1]區間均勻分布隨機數R,則產生X的反變換公式為:
F(x)=r, 即x=F-1(r)
反函數存在條件:如果函數y=f(x)是定義域D上的單調函數,那么f(x)一定有反函數存在,且反函數一定是單調的。分布函數F(x)為是一個單調遞增函數,所以其反函數存在。從直觀意義上理解,因為r一一對應著x,而在[0,1]均勻分布隨機數R≤r的概率P(R≤r)=r。 因此,連續隨機數X≤x的概率P(X≤x)=P(R≤r)=r=F(x)
即X的分布函數為F(x)。
例子:下面的代碼使用反變換法在區間[0, 6]上生成隨機數,其概率密度近似為P(x)=e-x
import numpy as npimport matplotlib.pyplot as plt# probability distribution we're trying to calculatep = lambda x: np.exp(-x)# CDF of pCDF = lambda x: 1-np.exp(-x)# invert the CDFinvCDF = lambda x: -np.log(1-x)# domain limitsxmin = 0 # the lower limit of our domainxmax = 6 # the upper limit of our domain# range limitsrmin = CDF(xmin)rmax = CDF(xmax)N = 10000 # the total of samples we wish to generate# generate uniform samples in our range then invert the CDF# to get samples of our target distributionR = np.random.uniform(rmin, rmax, N)X = invCDF(R)# get the histogram infohinfo = np.histogram(X,100)# plot the histogramplt.hist(X,bins=100, label=u'Samples');# plot our (normalized) functionxvals=np.linspace(xmin, xmax, 1000)plt.plot(xvals, hinfo[0][0]*p(xvals), 'r', label=u'p(x)')# turn on the legendplt.legend()plt.show()
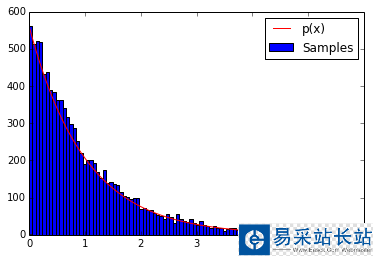
一般來說,直方圖的外廓曲線接近于總體X的概率密度曲線。
2.舍選抽樣法(Rejection Methold)
用反變換法生成隨機數時,如果求不出F-1(x)的解析形式或者F(x)就沒有解析形式,則可以用F-1(x)的近似公式代替。但是由于反函數計算量較大,有時也是很不適宜的。另一種方法是由Von Neumann提出的舍選抽樣法。下圖中曲線w(x)為概率密度函數,按該密度函數產生隨機數的方法如下:
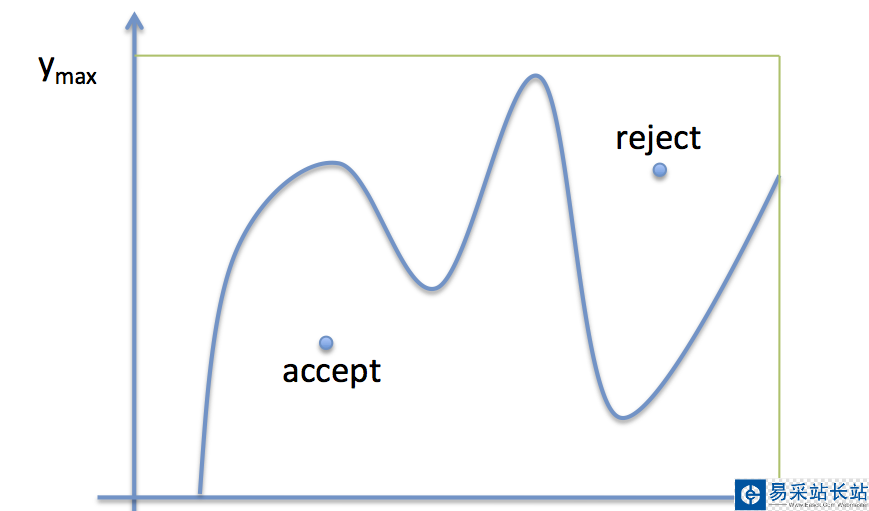
基本的rejection methold步驟如下:
1. Draw x uniformly from [xmin xmax]
2. Draw x uniformly from [0, ymax]
3. if y < w(x),accept the sample, otherwise reject it
4. repeat
即落在曲線w(x)和X軸所圍成區域內的點接受,落在該區域外的點舍棄。
例子:下面的代碼使用basic rejection sampling methold在區間[0, 10]上生成隨機數,其概率密度近似為P(x)=e-x
# -*- coding: utf-8 -*-'''The following code produces samples that follow the distribution P(x)=e^−x for x=[0, 10] and generates a histogram of the sampled distribution.'''import numpy as npimport matplotlib.pyplot as pltP = lambda x: np.exp(-x)# domain limitsxmin = 0 # the lower limit of our domainxmax = 10 # the upper limit of our domain# range limit (supremum) for yymax = 1N = 10000 # the total of samples we wish to generateaccepted = 0 # the number of accepted samplessamples = np.zeros(N)count = 0 # the total count of proposals# generation loopwhile (accepted < N): # pick a uniform number on [xmin, xmax) (e.g. 0...10) x = np.random.uniform(xmin, xmax) # pick a uniform number on [0, ymax) y = np.random.uniform(0,ymax) # Do the accept/reject comparison if y < P(x): samples[accepted] = x accepted += 1 count +=1 print count, accepted# get the histogram info# If bins is an int, it defines the number of equal-width bins in the given range (n, bins)= np.histogram(samples, bins=30) # Returns: n-The values of the histogram,n是直方圖中柱子的高度# plot the histogramplt.hist(samples,bins=30,label=u'Samples') # bins=30即直方圖中有30根柱子# plot our (normalized) functionxvals=np.linspace(xmin, xmax, 1000)plt.plot(xvals, n[0]*P(xvals), 'r', label=u'P(x)')# turn on the legendplt.legend()plt.show()
新聞熱點






疑難解答













