一、偽裝瀏覽器
對(duì)于一些需要登錄的網(wǎng)站,如果不是從瀏覽器發(fā)出的請(qǐng)求,則得不到響應(yīng)。所以,我們需要將爬蟲程序發(fā)出的請(qǐng)求偽裝成瀏覽器正規(guī)軍。
具體實(shí)現(xiàn):自定義網(wǎng)頁(yè)請(qǐng)求報(bào)頭。
二、使用Fiddler查看請(qǐng)求和響應(yīng)報(bào)頭
打開工具Fiddler,然后再瀏覽器訪問(wèn)“https://www.douban.com/”,在Fiddler左側(cè)訪問(wèn)記錄中,找到“200 HTTPS www.douban.com”這一條,點(diǎn)擊查看其對(duì)應(yīng)的請(qǐng)求和響應(yīng)報(bào)頭具體內(nèi)容:
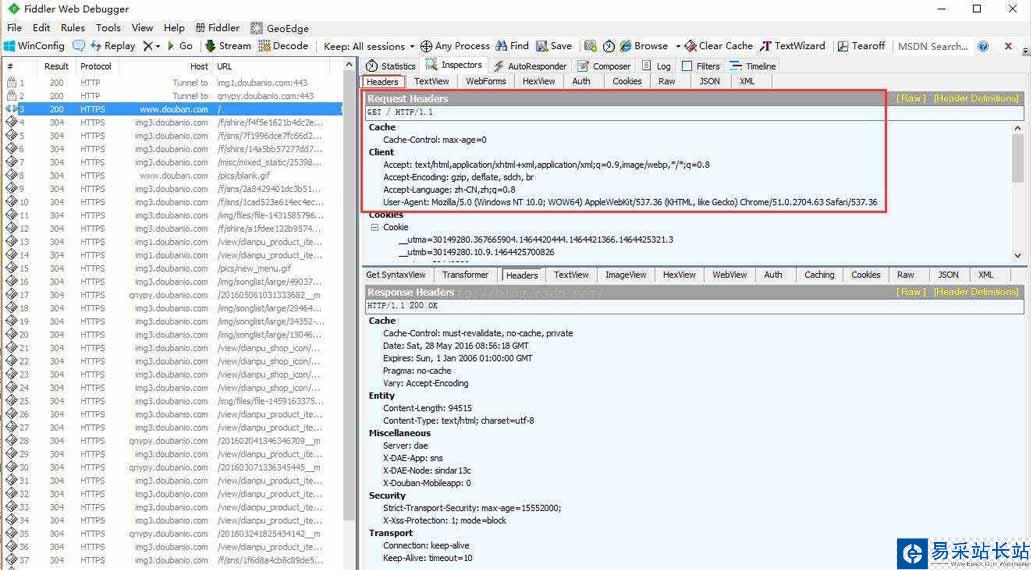
三、訪問(wèn)豆瓣
我們自定義請(qǐng)求報(bào)頭與上圖Request Headers相同內(nèi)容:
''''' 偽裝瀏覽器 對(duì)于一些需要登錄的網(wǎng)站,如果不是從瀏覽器發(fā)出的請(qǐng)求,則得不到響應(yīng)。 所以,我們需要將爬蟲程序發(fā)出的請(qǐng)求偽裝成瀏覽器正規(guī)軍。 具體實(shí)現(xiàn):自定義網(wǎng)頁(yè)請(qǐng)求報(bào)頭。 ''' #實(shí)例二:依然爬取豆瓣,采用偽裝瀏覽器的方式 import urllib.request #定義保存函數(shù) def saveFile(data): path = "E://projects//Spider//02_douban.out" f = open(path,'wb') f.write(data) f.close() #網(wǎng)址 url = "https://www.douban.com/" headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'} req = urllib.request.Request(url=url,headers=headers) res = urllib.request.urlopen(req) data = res.read() #也可以把爬取的內(nèi)容保存到文件中 saveFile(data) data = data.decode('utf-8') #打印抓取的內(nèi)容 print(data) #打印爬取網(wǎng)頁(yè)的各類信息 print(type(res)) print(res.geturl()) print(res.info()) print(res.getcode()) 四、輸出的結(jié)果結(jié)果(截取部分)
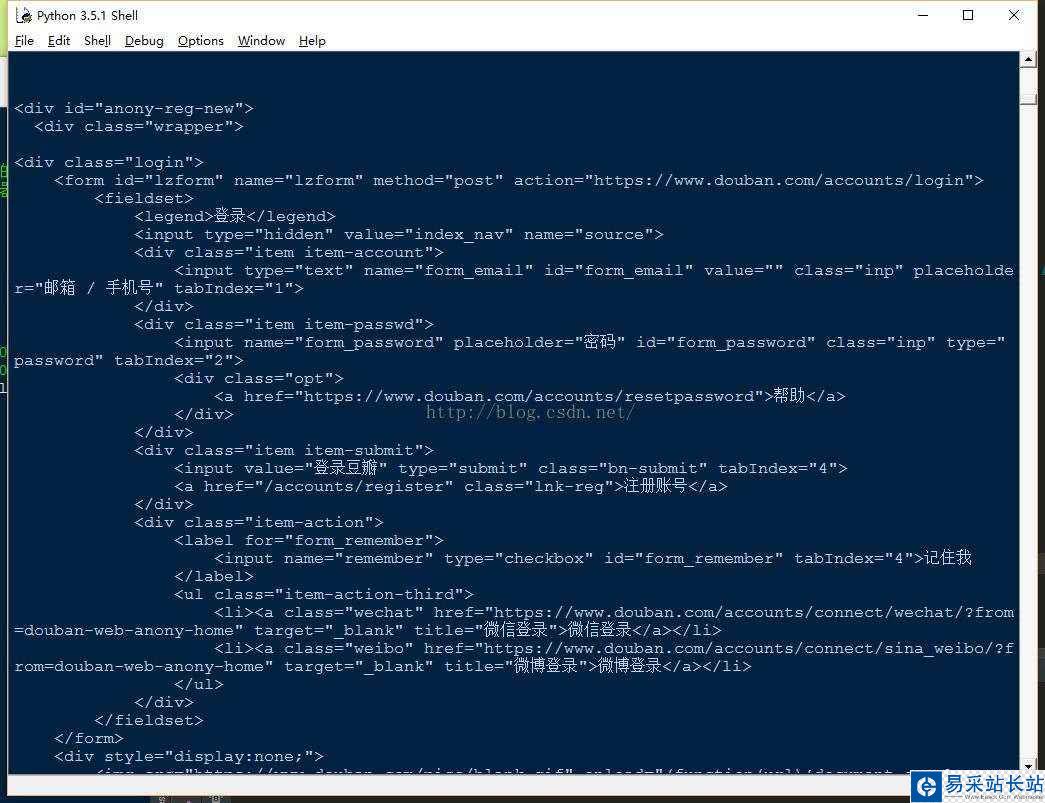
結(jié)果文件內(nèi)容
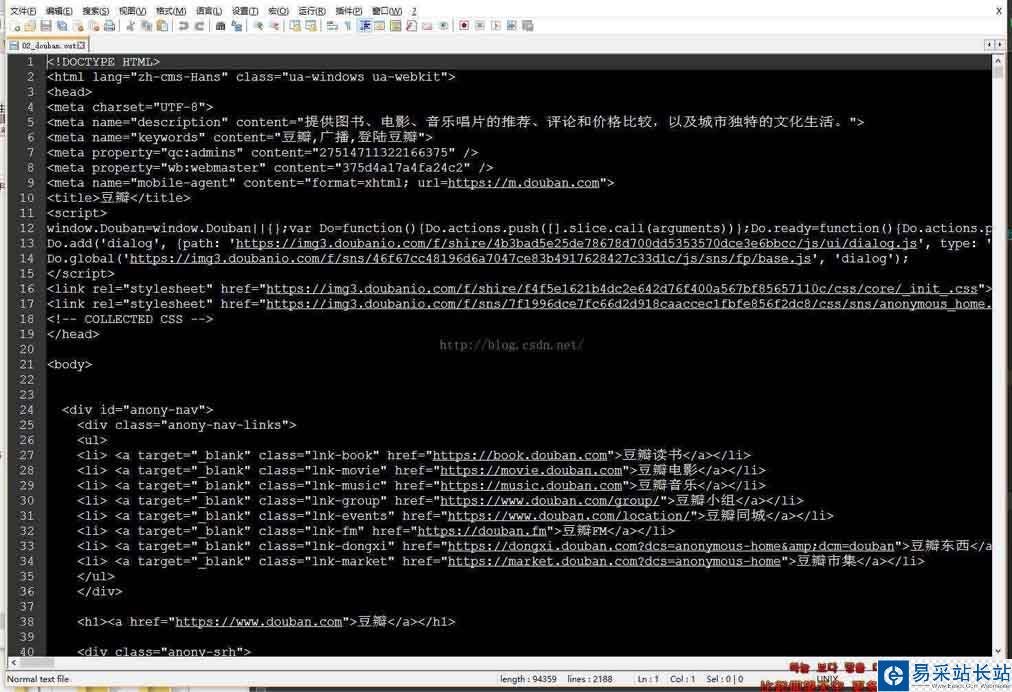
GitHub代碼鏈接
以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持武林站長(zhǎng)站。
新聞熱點(diǎn)






疑難解答
圖片精選













