這段時間看了數據分析方面的內容,對Python中的numpy和pandas有了最基礎的了解。我知道如果我不用這些技能做些什么的話,很快我就會忘記。想起之前群里發過一個學校的四六級成績表,正好可以用來熟悉一下pandas中的一些用法。
1.數據介紹。
成績表中包含的字段十分詳細,里面有年級、性別、姓名、分數等等的一系列內容,我只想簡單的分析一下我們學校的四六級過關率而已,所以去除了一些不必要的字段。留下的有如下幾個字段:
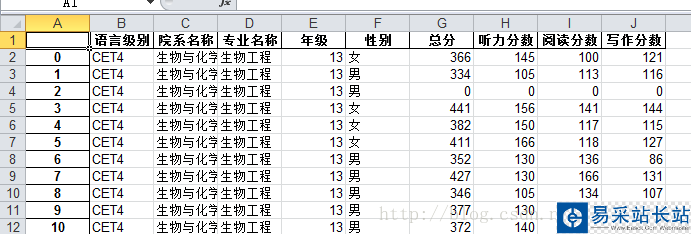
第一列是自增的序號,沒有什么實際意義。
第二列就是代表著該學生參加的是四級還是六級。
第三列是我們學校的院系名稱。
第四列是學校院系的各個專業。
第五列是年級,13代表著2013年入學。
第六列是性別。
后面的三列分別是總分、聽力、閱讀、寫作等。
其中總分為0的都是缺考的。一共有接近9000條數據(沒有報名的不在其中)。
2.預期結果。
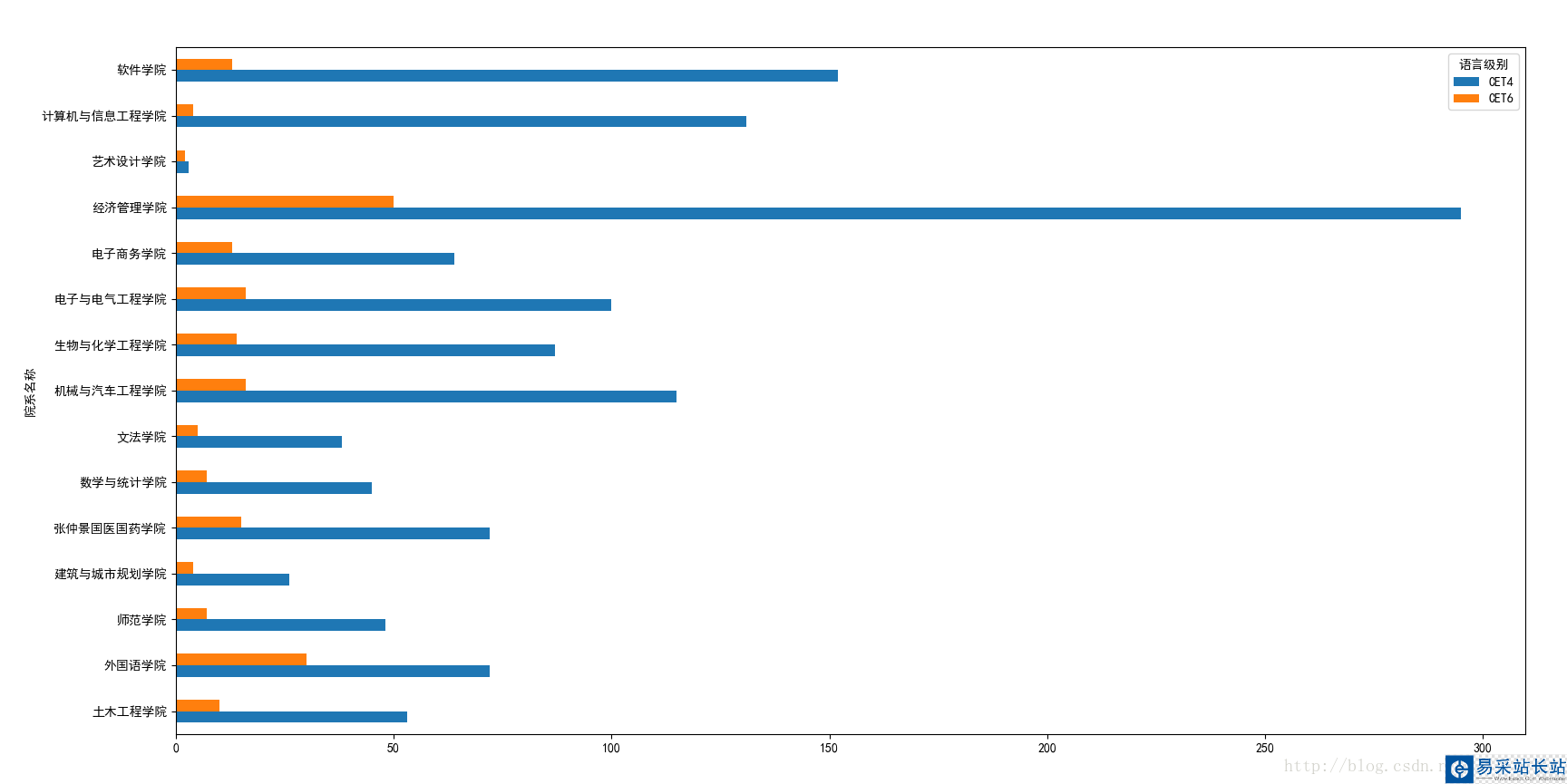
我想利用這些數據最終通過圖標的形式展示出以下幾點:
1.各個學院的四六級平均分。
2.各個學院的四六級過關人數。
3.各個學院的各個年級過關人數。
4.各個年級的過關人數。
5.男生女生分別過關人數。
最終結果:
各個學院的四六級過關人數:
3.實現過程。
(1)導入依賴包。
程序分別使用了pandas進行分組轉換,和matplotlib提供的繪圖功能。
import pandas as pdimport matplotlib.pylab as plt
(2)加載數據。
想要分析數據自然要得到數據了,我將整理的數據存放在sj.xls中,是一個Excel類型的數據。
這一步使用pandas的read_excel即可,生成一個DataFrame對象。
#加載全部數據sj = pd.read_excel(r'F:/DataAnalysis/sj.xls')
加載完之后輸出一下看看內容:
除了排版沒有對齊之外其他都一樣。
(3)統計各個學院平均分。
在這里就可以完成我們預期的第一個結果:
各個學院的四六級平均分:
想要各個學院的情況當然是要根據學院來進行分組了,同時也需要分出“CET4”和“CET6”兩組。使用groupby即可,這樣會生成一個SeriesGroupBy對象,然后再調用mean函數(默認是軸0計算,也就是我們想要的結果)即可統計出平均分情況。
#按照各個學院進行分組xymean = sj['總分'].groupby([sj['院系名稱'],sj['語言級別']])#計算各個學院的平均分數xymean = xymean.mean()
新聞熱點






疑難解答













