AlexNet是2012年ImageNet比賽的冠軍,雖然過去了很長時間,但是作為深度學(xué)習(xí)中的經(jīng)典模型,AlexNet不但有助于我們理解其中所使用的很多技巧,而且非常有助于提升我們使用深度學(xué)習(xí)工具箱的熟練度。尤其是我剛?cè)腴T深度學(xué)習(xí),迫切需要一個能讓自己熟悉tensorflow的小練習(xí),于是就有了這個小玩意兒......
先放上我的代碼:https://github.com/hjptriplebee/AlexNet_with_tensorflow
如果想運行代碼,詳細的配置要求都在上面鏈接的readme文件中了。本文建立在一定的tensorflow基礎(chǔ)上,不會對太細的點進行說明。
模型結(jié)構(gòu)
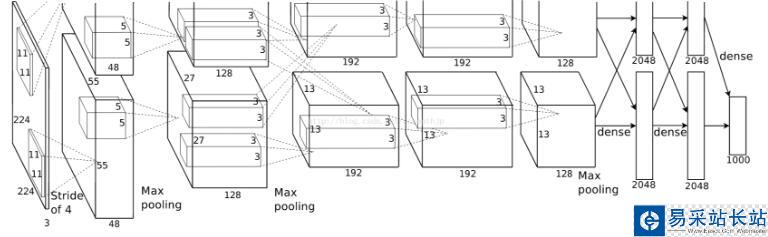
關(guān)于模型結(jié)構(gòu)網(wǎng)上的文獻很多,我這里不贅述,一會兒都在代碼里解釋。
有一點需要注意,AlexNet將網(wǎng)絡(luò)分成了上下兩個部分,在論文中兩部分結(jié)構(gòu)完全相同,唯一不同的是他們放在不同GPU上訓(xùn)練,因為每一層的feature map之間都是獨立的(除了全連接層),所以這相當(dāng)于是提升訓(xùn)練速度的一種方法。很多AlexNet的復(fù)現(xiàn)都將上下兩部分合并了,因為他們都是在單個GPU上運行的。雖然我也是在單個GPU上運行,但是我還是很想將最原始的網(wǎng)絡(luò)結(jié)構(gòu)還原出來,所以我的代碼里也是分開的。
模型定義
def maxPoolLayer(x, kHeight, kWidth, strideX, strideY, name, padding = "SAME"): """max-pooling""" return tf.nn.max_pool(x, ksize = [1, kHeight, kWidth, 1], strides = [1, strideX, strideY, 1], padding = padding, name = name) def dropout(x, keepPro, name = None): """dropout""" return tf.nn.dropout(x, keepPro, name) def LRN(x, R, alpha, beta, name = None, bias = 1.0): """LRN""" return tf.nn.local_response_normalization(x, depth_radius = R, alpha = alpha, beta = beta, bias = bias, name = name) def fcLayer(x, inputD, outputD, reluFlag, name): """fully-connect""" with tf.variable_scope(name) as scope: w = tf.get_variable("w", shape = [inputD, outputD], dtype = "float") b = tf.get_variable("b", [outputD], dtype = "float") out = tf.nn.xw_plus_b(x, w, b, name = scope.name) if reluFlag: return tf.nn.relu(out) else: return out def convLayer(x, kHeight, kWidth, strideX, strideY, featureNum, name, padding = "SAME", groups = 1):#group為2時等于AlexNet中分上下兩部分 """convlutional""" channel = int(x.get_shape()[-1])#獲取channel conv = lambda a, b: tf.nn.conv2d(a, b, strides = [1, strideY, strideX, 1], padding = padding)#定義卷積的匿名函數(shù) with tf.variable_scope(name) as scope: w = tf.get_variable("w", shape = [kHeight, kWidth, channel/groups, featureNum]) b = tf.get_variable("b", shape = [featureNum]) xNew = tf.split(value = x, num_or_size_splits = groups, axis = 3)#劃分后的輸入和權(quán)重 wNew = tf.split(value = w, num_or_size_splits = groups, axis = 3) featureMap = [conv(t1, t2) for t1, t2 in zip(xNew, wNew)] #分別提取feature map mergeFeatureMap = tf.concat(axis = 3, values = featureMap) #feature map整合 # print mergeFeatureMap.shape out = tf.nn.bias_add(mergeFeatureMap, b) return tf.nn.relu(tf.reshape(out, mergeFeatureMap.get_shape().as_list()), name = scope.name) #relu后的結(jié)果
新聞熱點






疑難解答













