前言
最近工作中遇到一個需求,需要將京東上圖書的圖片下載下來,假如我們想把京東商城圖書類的圖片類商品圖片全部下載到本地,通過手工復制粘貼將是一項非常龐大的工程,此時,可以用Python網絡爬蟲實現,這類爬蟲稱為圖片爬蟲,接下來,我們將實現該爬蟲。
實現分析
首先,打開要爬取的第一個網頁,這個網頁將作為要爬取的起始頁面。我們打開京東,選擇圖書分類,由于圖書所有種類的圖書有很多,我們選擇爬取所有編程語言的圖書圖片吧,網址為:https://list.jd.com/list.html?cat=1713,3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
如圖:
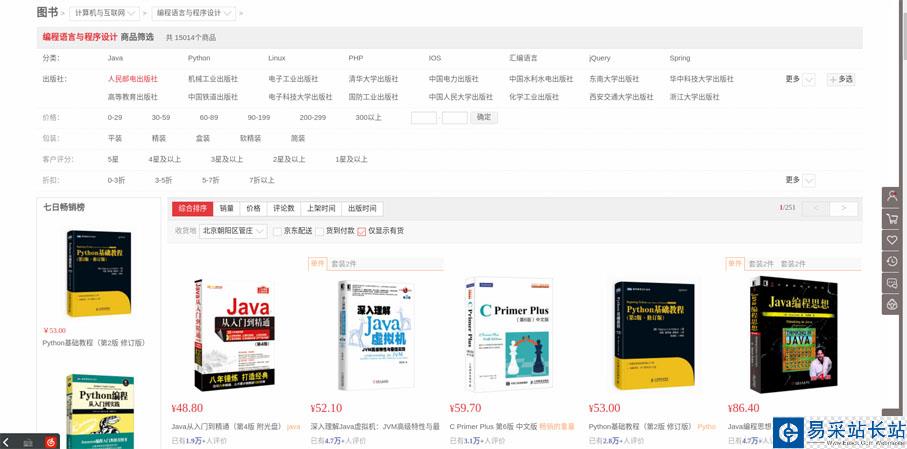
進去后,我們會發現總共有251頁。
那么我們怎么才能自動爬取第一頁以外的其他頁面呢?
可以單擊“下一頁”,觀察網址的變化。在單擊了下一頁之后,發現網址變成了https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main。
我們可以發現,在這里要獲取第幾頁是通過URL網址識別的,即通過GET方式請求的。在這個GET請求中,有多個字段,其中有一個字段為page,對應值為2,由此,我們可以得到該網址中的關鍵信息為:https://list.jd.com/list.html?cat=1713,3287,3797&page=2。接下來,我們根據推測,將page=2改成page=6,發現我們能夠成功進入第6頁。
由此,我們可以想到自動獲取多個頁面的方法:可以使用for循環實現,每次循環后,對應的網址中page字段加1,即自動切換到下一頁。
在每頁中,我們都要提取對應的圖片,可以使用正則表達式匹配源碼中圖片的鏈接部分,然后通過urllib.request.urlretrieve()將對應鏈接的圖片保存到本地。
但是這里有一個問題,該網頁中的圖片不僅包括列表中的商品圖片,還包括旁邊的一些無關圖片,所以我們可以先進行一次信息過濾,第一次信息過濾將中間的商品列表部分數據留下,將其他部分的數據過濾掉。可以單擊右鍵,然后查看網頁的源代碼,如圖:
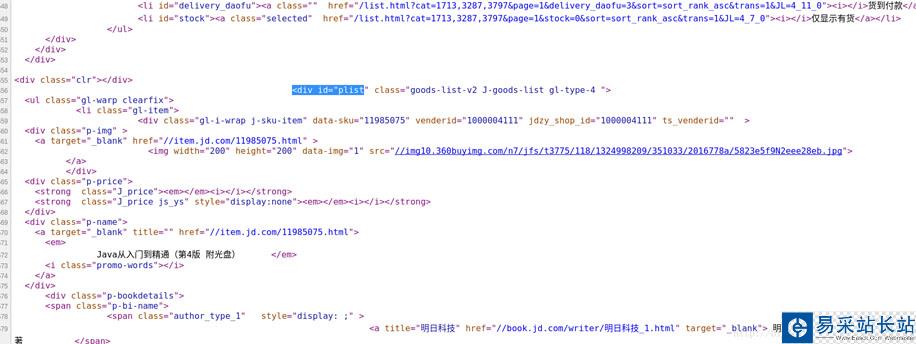
可以通過商品列表中的第一個商品名為“JAVA從入門到精通”快速定位到源碼中的對應位置,然后觀察其商品列表部分的特殊標識,可以看到,其上方有處“<div id="plist”代碼,然后我們在源碼中搜索該代碼,發現只有一個地方有,隨后打開其他頁的對應頁面,發現仍然具有這個規律,說明該特殊標識可以作為有效信息的起始過濾位置。當然,你可以使用其他的代碼作為特殊標識,但是該特殊標識要滿足唯一性,并且要包含要爬取的信息。
新聞熱點






疑難解答













