前言
相信大家初入某個(gè)項(xiàng)目,一般都要看代碼。有時(shí)候,想把代碼文件打印下來(lái)看,不過(guò)一般代碼文件數(shù)量都在兩位數(shù)或更多,逐一打開(kāi)、打印,確實(shí)太耗費(fèi)精力了,此外,也會(huì)出現(xiàn)某個(gè)代碼文件打印到紙上只占了一兩行的情況,很浪費(fèi)紙。如果可以合并到一個(gè)文本文件里面上面這些問(wèn)題就解決。
目前一個(gè)用的比較多的功能:將多個(gè)小文件的內(nèi)容合并在一個(gè)統(tǒng)一的文件中,對(duì)原始文件重命名標(biāo)記其已被處理過(guò)。
之前使用其他腳本寫的,嘗試用python寫了一下,順便熟悉一下python的文件處理命令。
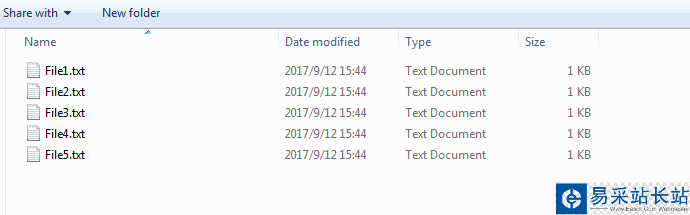
原始文件
經(jīng)過(guò)處理之后
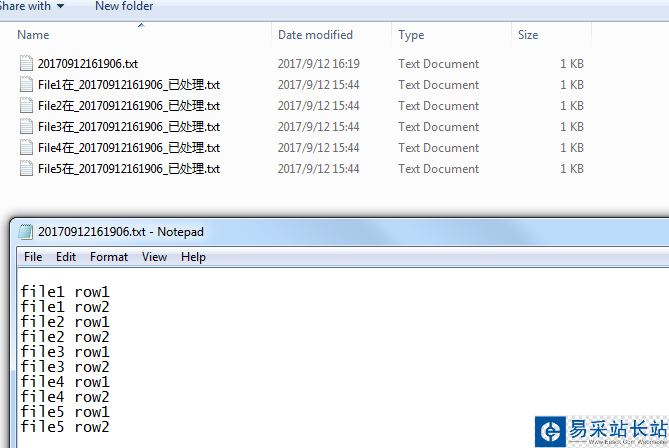
最后還有一個(gè)蛋疼的因?yàn)榭s進(jìn)產(chǎn)生的第一個(gè)回車符
其中包含了文件的創(chuàng)建和移除,文件內(nèi)容的讀寫,文件的重命名的語(yǔ)法命令等等
示例代碼
# -*- coding: utf-8 -*-import osimport timeimport datetimedef merge_file(file_path,file_name): #file_path must exits if(os.path.exists(file_path) is False): print('file_path is not exists') return if(os.path.exists(os.path.join(file_path, file_name))): os.remove(os.path.join(file_path, file_name)) #'%Y_%m_%d%H%M%S',創(chuàng)建一個(gè)以日期命名的文本文件 targetfilename = str(time.strftime('%Y%m%d%H%M%S'))+'.txt' fobj = open(os.path.join(file_path, targetfilename), 'w') fobj.close() # a 是以追加的方式打開(kāi)文件寫入 with open(os.path.join(file_path, targetfilename), 'a', encoding='GBK') as f_wirte: files = os.listdir(file_path) for file in files: print(os.path.join(file_path, file)) with open(file_path+'//'+file, 'r', encoding='GBK') as f: for line in f.readlines(): if(line.strip().__len__()) > 0:# 排除空行 f_wirte.write(line) f_wirte.write('/n')# 每讀完一個(gè)文件之后,加一個(gè)回車,否則第一個(gè)文件的最后一行跟第二個(gè)文件的第一行沒(méi)有回車 # 文件合并之后,重命名原始的文件, # os.path.splitext(file)[0] 提取文件名,不包括后綴名 # os.path.splitext(file)[1] 提取文件后綴名 if (file != targetfilename): os.rename(os.path.join(file_path, file),os.path.join(file_path, os.path.splitext(file)[0] + '在_' +str(time.strftime('%Y%m%d%H%M%S')) +'_已處理' + '.txt'))merge_file('D:/TestPythonMergeFile','auoto_create_a_category_file')總結(jié)
以上就是這篇文章的全部?jī)?nèi)容了,希望本文的內(nèi)容對(duì)大家的學(xué)習(xí)或者工作能帶來(lái)一定的幫助,如果有疑問(wèn)大家可以留言交流,謝謝大家對(duì)武林站長(zhǎng)站的支持。
新聞熱點(diǎn)






疑難解答
圖片精選













