本文主要給大家介紹的是關于python爬取散文網文章的相關內容,分享出來供大家參考學習,下面一起來看看詳細的介紹:
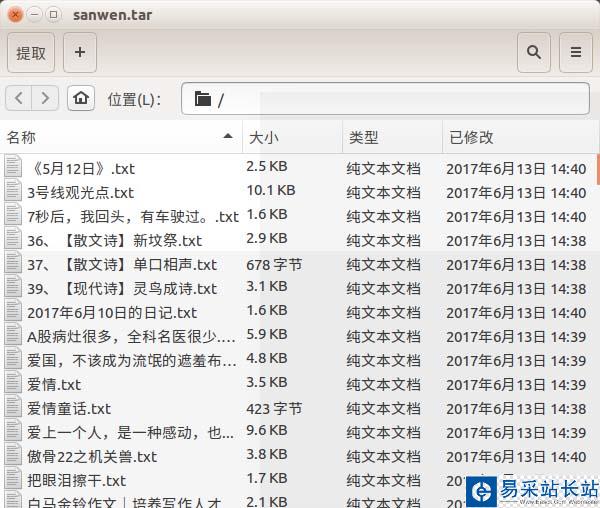
效果圖如下:
配置python 2.7
bs4 requests
安裝 用pip進行安裝 sudo pip install bs4
sudo pip install requests
簡要說明一下bs4的使用因為是爬取網頁 所以就介紹find 跟find_all
find跟find_all的不同在于返回的東西不同 find返回的是匹配到的第一個標簽及標簽里的內容
find_all返回的是一個列表
比如我們寫一個test.html 用來測試find跟find_all的區別。
內容是:
<html><head></head><body><div id="one"><a></a></div><div id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></div><div id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></div><div id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></div></body></html>
然后test.py的代碼為:
from bs4 import BeautifulSoupimport lxmlif __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"運行以后我們可以看到結果當獲取指定標簽時候兩者區別不大當獲取一組標簽的時候兩者的區別就會顯示出來
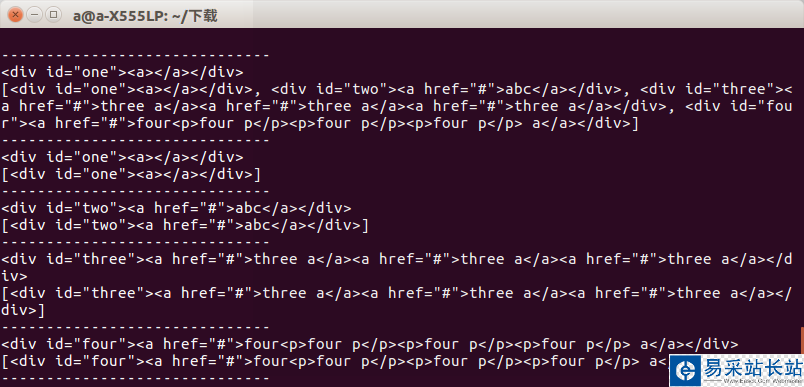
所以我們在使用時候要注意到底要的是什么,否則會出現報錯
新聞熱點






疑難解答













