前言
對于經常寫爬蟲的大家都知道,有些頁面在登錄之前是被禁止抓取的,比如知乎的話題頁面就要求用戶登錄才能訪問,而 “登錄” 離不開 HTTP 中的 Cookie 技術。
登錄原理
Cookie 的原理非常簡單,因為 HTTP 是一種無狀態的協議,因此為了在無狀態的 HTTP 協議之上維護會話(session)狀態,讓服務器知道當前是和哪個客戶在打交道,Cookie 技術出現了 ,Cookie 相當于是服務端分配給客戶端的一個標識。
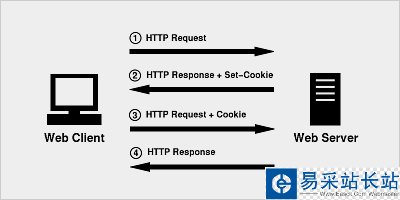
實戰應用
用過知乎的都知道,只要提供用戶名和密碼以及驗證碼之后即可登錄。當然,這只是我們眼中看到的現象。而背后隱藏的技術細節就需要借助瀏覽器來挖掘了。現在我們就用 Chrome 來查看當我們填完表單后,究竟發生了什么?
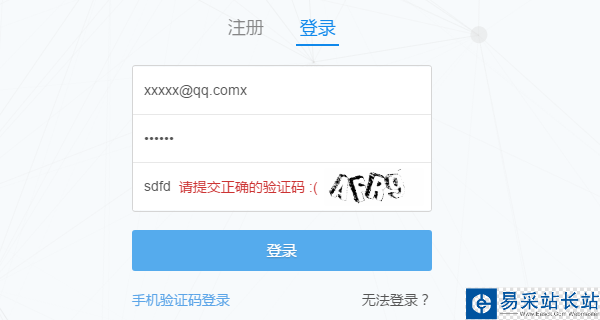
(如果已經登錄的,先退出)首先進入知乎的登錄頁面 https://www.zhihu.com/#signin ,打開 Chrome 的開發者工具條(按 F12)先嘗試輸入一個錯誤的驗證碼觀察瀏覽器是如何發送請求的。
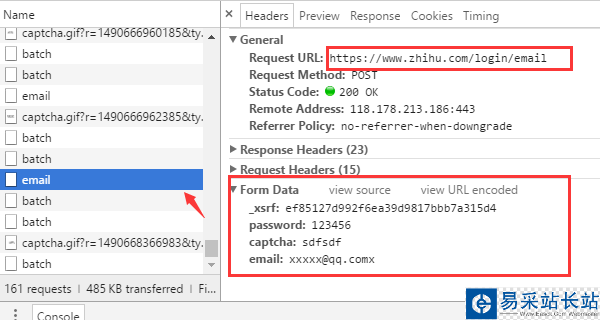
從瀏覽器的請求可以發現幾個關鍵的信息
登錄的 URL 地址是 https://www.zhihu.com/login/email 登錄需要提供的表單數據有4個:用戶名(email)、密碼(password)、驗證碼(captcha)、_xsrf。 獲取驗證碼的URL地址是 https://www.zhihu.com/captcha.gif?r=1490690391695&type=login_xsrf 是什么?如果你對CSRF(跨站請求偽造)攻擊非常熟悉的話,那么你一定知道它的作用,xsrf是一串偽隨機數,它是用于防止跨站請求偽造的。它一般存在網頁的 form 表單標簽中,為了證實這一點,可以在頁面上搜索 “xsrf”,果然,_xsrf在一個隱藏的 input 標簽中

摸清了瀏覽器登錄時所需要的數據是如何獲取之后,那么現在就可以開始寫代碼用 Python 模擬瀏覽器來登錄了。登錄時所依賴的兩個第三方庫是 requests 和 BeautifulSoup,先安裝
pip install beautifulsoup4==4.5.3pip install requests==2.13.0
http.cookiejar 模塊可用于自動處理HTTP Cookie,LWPCookieJar 對象就是對 cookies 的封裝,它支持把 cookies 保存到文件以及從文件中加載。
新聞熱點






疑難解答













