一、I/O模型
IO在計算機中指Input/Output,也就是輸入和輸出。由于程序和運行時數據是在內存中駐留,由CPU這個超快的計算核心來執行,涉及到數據交換的地方,通常是磁盤、網絡等,就需要IO接口。
同步(synchronous) IO和異步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分別是什么,到底有什么區別?
這個問題其實不同的人給出的答案都可能不同,比如wiki,就認為asynchronous IO和non-blocking IO是一個東西。這其實是因為不同的人的知識背景不同,并且在討論這個問題的時候上下文(context)也不相同。所以,為了更好的回答這個問題,先限定一下本文的上下文。
本文討論的背景是Linux環境下的network IO。
Stevens在文章中一共比較了五種IO Model:
blocking IO(阻塞IO)
nonblocking IO (非阻塞IO)
IO multiplexing (IO多路復用)
asynchronous IO (異步IO)
signal driven IO (信號驅動IO)
由于signal driven IO在實際中并不常用,所以我這只提及剩下的四種IO Model。
再說一下IO發生時涉及的對象和步驟。
對于一個network IO (這里我們以read舉例),它會涉及到兩個系統對象,一個是調用這個IO的process (or thread),另一個就是系統內核(kernel)。當一個read操作發生時,它會經歷兩個階段:
等待數據準備 (Waiting for the data to be ready)
將數據從內核拷貝到進程中 (Copying the data from the kernel to the process)
記住這兩點很重要,因為這些IO Model的區別就是在兩個階段上各有不同的情況。
二、 blocking IO
在linux中,默認情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:
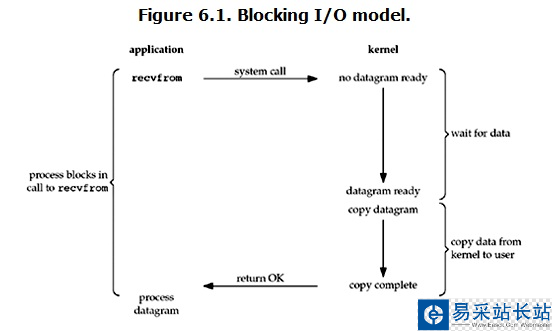
當用戶進程調用了recvfrom這個系統調用,kernel就開始了IO的第一個階段:準備數據。對于network IO來說,很多時候數據在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的數據到來。而在用戶進程這邊,整個進程會被阻塞。當kernel一直等到數據準備好了,它就會將數據從kernel中拷貝到用戶內存,然后kernel返回結果,用戶進程才解除block的狀態,重新運行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
三、non-blocking IO
linux下,可以通過設置socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:
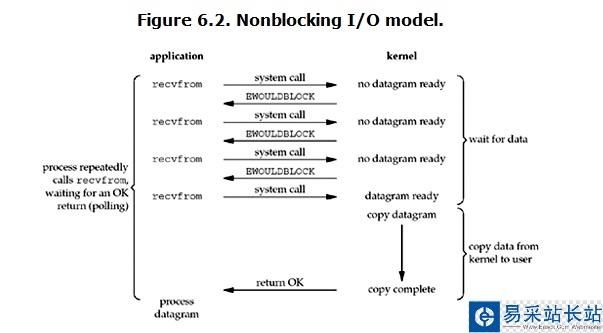
從圖中可以看出,當用戶進程發出read操作時,如果kernel中的數據還沒有準備好,那么它并不會block用戶進程,而是立刻返回一個error。從用戶進程角度講 ,它發起一個read操作后,并不需要等待,而是馬上就得到了一個結果。用戶進程判斷結果是一個error時,它就知道數據還沒有準備好,于是它可以再次發送read操作。一旦kernel中的數據準備好了,并且又再次收到了用戶進程的system call,那么它馬上就將數據拷貝到了用戶內存,然后返回。所以,用戶進程其實是需要不斷的主動詢問kernel數據好了沒有。
新聞熱點






疑難解答













