在多數的現代語音識別系統中,人們都會用到頻域特征。梅爾頻率倒譜系數(MFCC),首先計算信號的功率譜,然后用濾波器和離散余弦變換的變換來提取特征。本文重點介紹如何提取MFCC特征。
首先創建有一個Python文件,并導入庫文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt1、首先創建有一個Python文件,并導入庫文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt
讀取音頻文件:
samplimg_freq, audio = wavfile.read("data/input_freq.wav")
提取MFCC特征和過濾器特征:
mfcc_features = mfcc(audio, samplimg_freq)
filterbank_features = logfbank(audio, samplimg_freq)


打印參數,查看可生成多少個窗體:
print('/nMFCC:/nNumber of windows =', mfcc_features.shape[0]) print('Length of each feature =', mfcc_features.shape[1]) print('/nFilter bank:/nNumber of windows=', filterbank_features.shape [0]) print('Length of each feature =', filterbank_features.shape[1])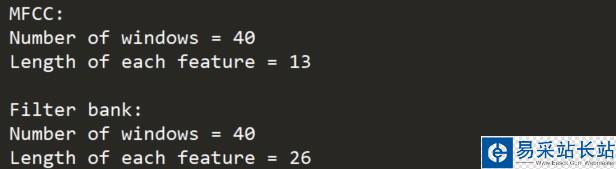
將MFCC特征可視化。轉換矩陣,使得時域是水平的:
mfcc_features = mfcc_features.T plt.matshow(mfcc_features) plt.title('MFCC')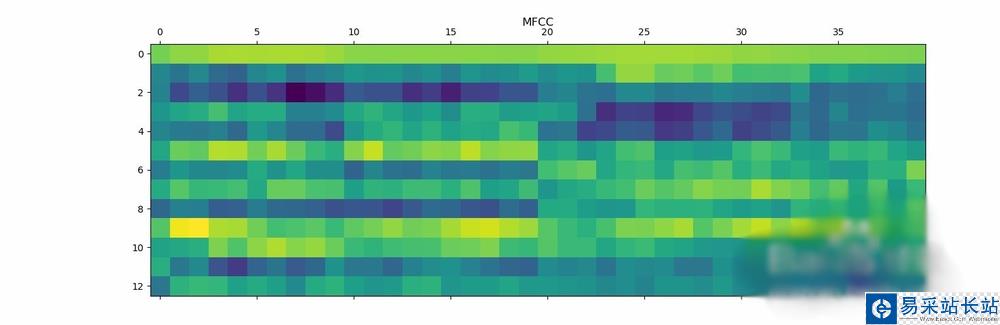
將濾波器組特征可視化。轉化矩陣,使得時域是水平的:
filterbank_features = filterbank_features.T plt.matshow(filterbank_features) plt.title('Filter bank') plt.show()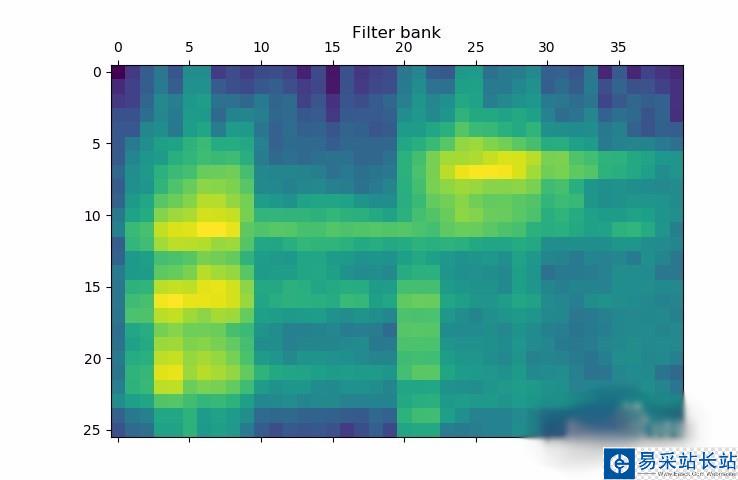
新聞熱點






疑難解答













