最近也是學(xué)習(xí)了一些爬蟲方面的知識(shí)。以我自己的理解,通常我們用瀏覽器查看網(wǎng)頁(yè)時(shí),是通過瀏覽器向服務(wù)器發(fā)送請(qǐng)求,然后服務(wù)器響應(yīng)以后返回一些代碼數(shù)據(jù),再經(jīng)過瀏覽器解析后呈現(xiàn)出來(lái)。而爬蟲則是通過程序向服務(wù)器發(fā)送請(qǐng)求,并且將服務(wù)器返回的信息,通過一些處理后,就能得到我們想要的數(shù)據(jù)了。
以下是前段時(shí)間我用python寫的一個(gè)爬取TX新聞標(biāo)題及其網(wǎng)址的一個(gè)簡(jiǎn)單爬蟲:
首先需要用到python中requests(方便全面的http請(qǐng)求庫(kù))和 BeautifulSoup(html解析庫(kù))。
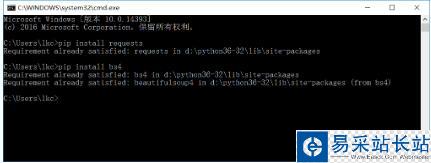
通過pip來(lái)安裝這兩個(gè)庫(kù),命令分別是:pip install requests 和 pip install bs4 (如下圖)
先放上完整的代碼
# coding:utf-8import requestsfrom bs4 import BeautifulSoup url = "http://news.qq.com/"# 請(qǐng)求騰訊新聞的URL,獲取其text文本wbdata = requests.get(url).text# 對(duì)獲取到的文本進(jìn)行解析soup = BeautifulSoup(wbdata,'lxml')# 從解析文件中通過select選擇器定位指定的元素,返回一個(gè)列表news_titles = soup.select("div.text > em.f14 > a.linkto") # 對(duì)返回的列表進(jìn)行遍歷for n in news_titles: title = n.get_text() link = n.get("href") data = { '標(biāo)題':title, '鏈接':link } print(data)首先引入上述兩個(gè)庫(kù)
import requestsfrom bs4 import BeautifulSoup
然后get請(qǐng)求騰訊新聞網(wǎng)url,返回的字符串實(shí)質(zhì)上就是我們手動(dòng)打開這個(gè)網(wǎng)站,然后查看網(wǎng)頁(yè)源代碼所看到的html代碼。
wbdata = requests.get(url).text
我們需要的僅僅是某些特定標(biāo)簽里的內(nèi)容:
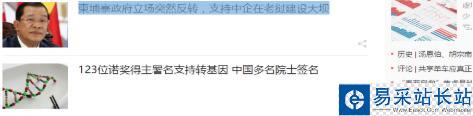
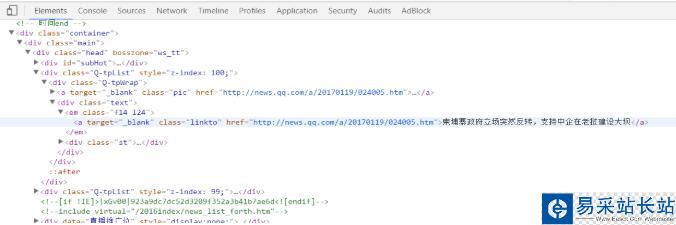
可以看出,每條新聞鏈接、標(biāo)題都在<div class="text">標(biāo)簽的<em class="f14 124">標(biāo)簽下
之后我們將剛剛請(qǐng)求得到的html代碼進(jìn)行處理,這時(shí)候就需要用到BeautifulSoap庫(kù)了
soup = BeautifulSoup(wbdata,'lxml')
這一行的意思是對(duì)獲取的信息進(jìn)行解析處理,也可以將lxml庫(kù)換成html.parser庫(kù),效果是相同的
news_titles = soup.select("div.text > em.f14 > a.linkto")這一行是利用剛剛經(jīng)過解析獲取的soup對(duì)象,選擇我們需要的標(biāo)簽,返回值是一個(gè)列表。列表中存放了我們需要的所有標(biāo)簽內(nèi)容。也可以使用BeautifulSoup中的find()方法或findall()方法來(lái)對(duì)標(biāo)簽進(jìn)行選擇。
最后用 for in 對(duì)列表進(jìn)行遍歷,分別取出標(biāo)簽中的內(nèi)容(新聞標(biāo)題)和標(biāo)簽中href的值(新聞網(wǎng)址),存放在data字典中
新聞熱點(diǎn)






疑難解答
圖片精選













