使用TensorFlow構建一個神經網絡來實現二分類,主要包括輸入數據格式、隱藏層數的定義、損失函數的選擇、優化函數的選擇、輸出層。下面通過numpy來隨機生成一組數據,通過定義一種正負樣本的區別,通過TensorFlow來構造一個神經網絡來實現二分類。
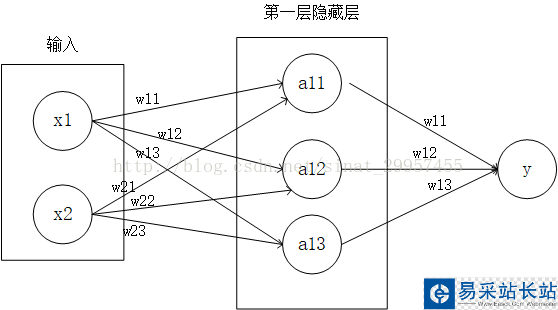
一、神經網絡結構
輸入數據:定義輸入一個二維數組(x1,x2),數據通過numpy來隨機產生,將輸出定義為0或1,如果x1+x2<1,則y為1,否則y為0。
隱藏層:定義兩層隱藏層,隱藏層的參數為(2,3),兩行三列的矩陣,輸入數據通過隱藏層之后,輸出的數據為(1,3),t通過矩陣之間的乘法運算可以獲得輸出數據。
損失函數:使用交叉熵作為神經網絡的損失函數,常用的損失函數還有平方差。
優化函數:通過優化函數來使得損失函數最小化,這里采用的是Adadelta算法進行優化,常用的還有梯度下降算法。
輸出數據:將隱藏層的輸出數據通過(3,1)的參數,輸出一個一維向量,值的大小為0或1。
二、TensorFlow代碼的實現
import tensorflow as tffrom numpy.random import RandomState if __name__ == "__main__": #定義每次訓練數據batch的大小為8,防止內存溢出 batch_size = 8 #定義神經網絡的參數 w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #定義輸入和輸出 x = tf.placeholder(tf.float32,shape=(None,2),name="x-input") y_ = tf.placeholder(tf.float32,shape=(None,1),name="y-input") #定義神經網絡的前向傳播過程 a = tf.matmul(x,w1) y = tf.matmul(a,w2) #定義損失函數和反向傳播算法 #使用交叉熵作為損失函數 #tf.clip_by_value(t, clip_value_min, clip_value_max,name=None) #基于min和max對張量t進行截斷操作,為了應對梯度爆發或者梯度消失的情況 cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0))) # 使用Adadelta算法作為優化函數,來保證預測值與實際值之間交叉熵最小 train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) #通過隨機函數生成一個模擬數據集 rdm = RandomState(1) # 定義數據集的大小 dataset_size = 128 # 模擬輸入是一個二維數組 X = rdm.rand(dataset_size,2) #定義輸出值,將x1+x2 < 1的輸入數據定義為正樣本 Y = [[int(x1+x2 < 1)] for (x1,x2) in X] #創建會話運行TensorFlow程序 with tf.Session() as sess: #初始化變量 tf.initialize_all_variables() init = tf.initialize_all_variables() sess.run(init) #設置神經網絡的迭代次數 steps = 5000 for i in range(steps): #每次選取batch_size個樣本進行訓練 start = (i * batch_size) % dataset_size end = min(start + batch_size,dataset_size) #通過選取樣本訓練神經網絡并更新參數 sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]}) #每迭代1000次輸出一次日志信息 if i % 1000 == 0 : # 計算所有數據的交叉熵 total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y}) # 輸出交叉熵之和 print("After %d training step(s),cross entropy on all data is %g"%(i,total_cross_entropy)) #輸出參數w1 print(w1.eval(session=sess)) #輸出參數w2 print(w2.eval(session=sess)) ''' After 0 training step(s),cross entropy on all data is 0.0674925 After 1000 training step(s),cross entropy on all data is 0.0163385 After 2000 training step(s),cross entropy on all data is 0.00907547 After 3000 training step(s),cross entropy on all data is 0.00714436 After 4000 training step(s),cross entropy on all data is 0.00578471 [[-1.96182752 2.58235407 1.68203771] [-3.46817183 1.06982315 2.11788988]] [[-1.82471502] [ 2.68546653] [ 1.41819501]] '''
新聞熱點






疑難解答













