1. 建立一個(gè)DataFrame
C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]})
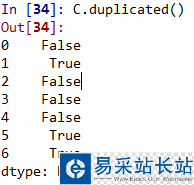
2. 判斷是否有重復(fù)項(xiàng)
用duplicated( )函數(shù)判斷
C.duplicated()
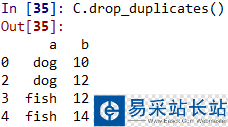
3. 有重復(fù)項(xiàng),則可以用drop_duplicates()移除重復(fù)項(xiàng)
C.drop_duplicates()
4. Duplicated( )和drop_duplicates( )方法是以默認(rèn)的方式判斷全部的列(上面的例子中是看兩個(gè)變量a和b是否都是重復(fù)出現(xiàn))。
我們也可以對特定的列進(jìn)行重復(fù)項(xiàng)判斷。
C.duplicated(['a']) C.drop_duplicates(['a']) C.duplicated(['b']) C.drop_duplicates(['b'])

5. norepeat_df = df.drop_duplicates(subset=['A_ID', 'B_ID'], keep='first')
#上面的命令去掉UNIT_ID和KPI_ID列中重復(fù)的行,并保留重復(fù)出現(xiàn)的行中第一次出現(xiàn)的行
補(bǔ)充:
當(dāng)keep=False時(shí),就是去掉所有的重復(fù)行 當(dāng)keep=‘first'時(shí),就是保留第一次出現(xiàn)的重復(fù)行 當(dāng)keep='last'時(shí)就是保留最后一次出現(xiàn)的重復(fù)行。(注意,這里的參數(shù)是字符串,要加引號(hào)!!!)
以上就是本文的全部內(nèi)容,希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持武林站長站。
新聞熱點(diǎn)






疑難解答
圖片精選













