無論是是自動化登錄還是爬蟲,總繞不開驗證碼,這次就來談?wù)刾ython中光學識別驗證碼模塊tesserocr和pytesseract。tesserocr和pytesseract是Python的一個OCR識別庫,但其實是對tesseract做的一層Python API封裝,pytesseract是Google的Tesseract-OCR引擎包裝器;所以它們的核心是tesseract,因此在安裝tesserocr之前,我們需要先安裝tesseract。
下載安裝
下載地址:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.0.0.20181030.exe
下載完成后,雙擊安裝,可以勾選Additional language data(download)選項來安裝OCR識別支持的語言包,但下載語言包實在是慢,我們可以直接從https://github.com/tesseract-ocr/tessdata/下載zip的語言包壓縮文件,解壓后將tessdata-master中的文件復(fù)制到Tesseract的安裝目錄C:/Program Files (x86)/Tesseract-OCR/tessdata目錄下,最后我們配置下環(huán)境變量,我們將C:/Program Files (x86)/Tesseract-OCR添加到環(huán)境變量中。進入命令提示符,輸入tesseract,顯示下圖結(jié)果,說明配置完成
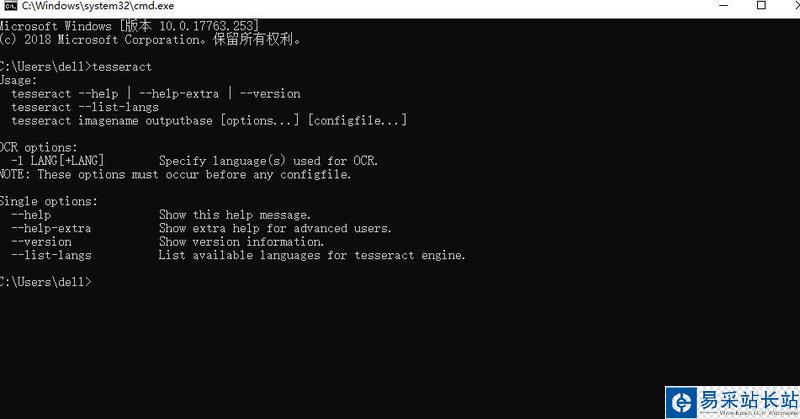
查看安裝了的語言包:tesseract --list-langs
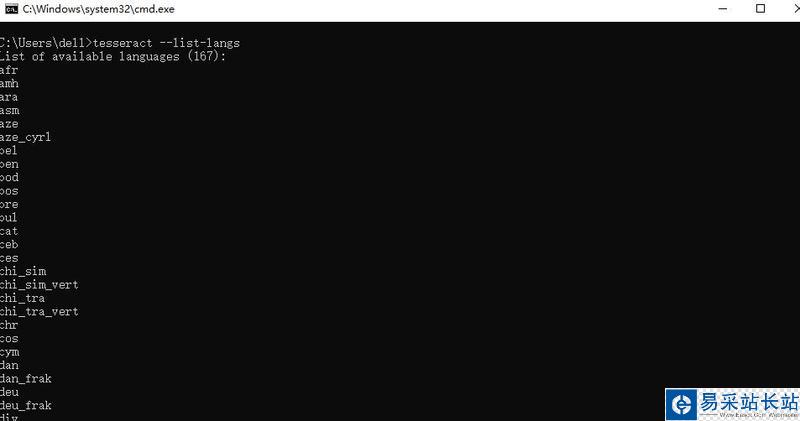
顯示我一共安裝了167種語言包,里邊包含英文或者其他字符。
測試
實驗用的二維碼
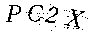
基本使用語法tesseract image.png result (tesseract 圖片名稱 生成文件名稱)
結(jié)果

由結(jié)果來看,識別出來了P、2和X,但是把C識別成了G,識別度還是比較高,接下來看在python中的使用
python引入tesseract
在python下使用pip命令即可完成下載安裝 pip install pytesseract
識別驗證碼腳本
import pytesseractfrom PIL import Imageim=Image.open('pin.png')print(pytesseract.image_to_string(im))結(jié)果
這樣識別的結(jié)果同樣跟上文一樣,個別字符識別的不是很準確
圖像處理
現(xiàn)在網(wǎng)站上的二維碼設(shè)計的通常很難復(fù)雜,如果直接識別的話很難識別出來,下面這段代碼是進行灰度處理和二值化
import pytesseractfrom PIL import Imageim=Image.open('5.jpg')#進行置灰處理im=im.convert('L')#這個是二值化閾值threshold=150table=[]for i in range(256): if i<threshold: table.append(0) else: table.append(1)#通過表格轉(zhuǎn)換成二進制圖片,1的作用是白色,0就是黑色im=im.point(table,"1")im.show()print(pytesseract.image_to_string(im))
新聞熱點






疑難解答













