一提到python,大家經常會提到爬蟲,爬蟲近來興起的原因我覺得主要還是因為大數據的原因,大數據導致了我們的數據不在只存在于自己的服務器,而python語言的簡便也成了爬蟲工具的首要語言,我們這篇文章來講下爬蟲,爬取新浪新聞
1、大家知道,爬蟲實際上就是模擬瀏覽器請求,然后把請求到的數據,經過我們的分析,提取出我們想要的內容,這也就是爬蟲的實現大家知道,爬蟲實際上就是模擬瀏覽器請求,然后把請求到的數據,經過我們的分析,提取出我們想要的內容,這也就是爬蟲的實現
2、首先,我們要寫爬蟲,可以借鑒一些工具,我們先從簡單的入門,首先說到請求,我們就會想到python中,非常好用的requests,然后說到分析解析就會用到bs4,然后我們可以直接用pip命令來實現安裝,假如安裝的是python3,也可以用pip3
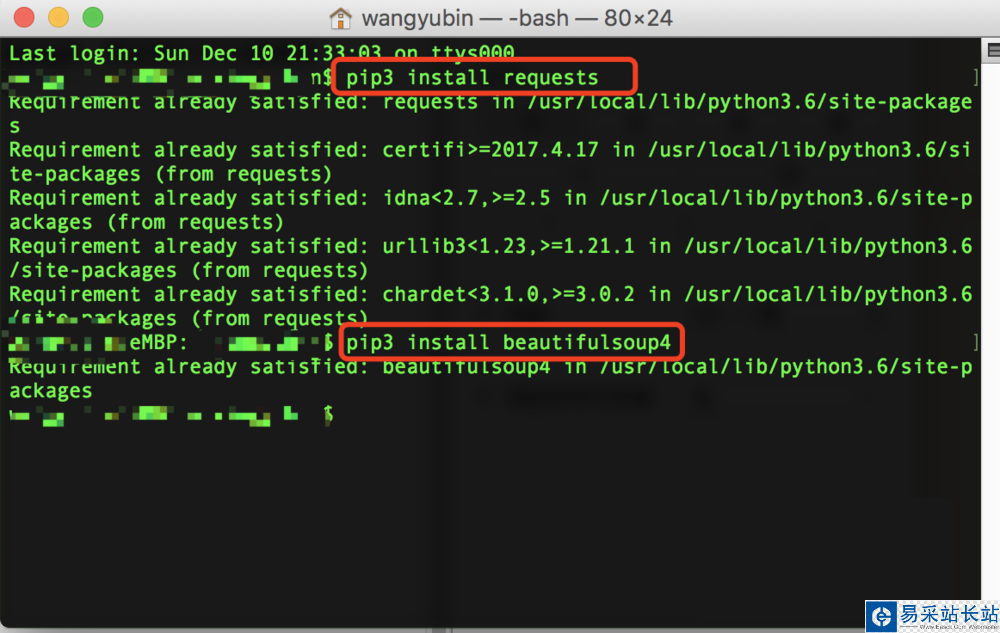
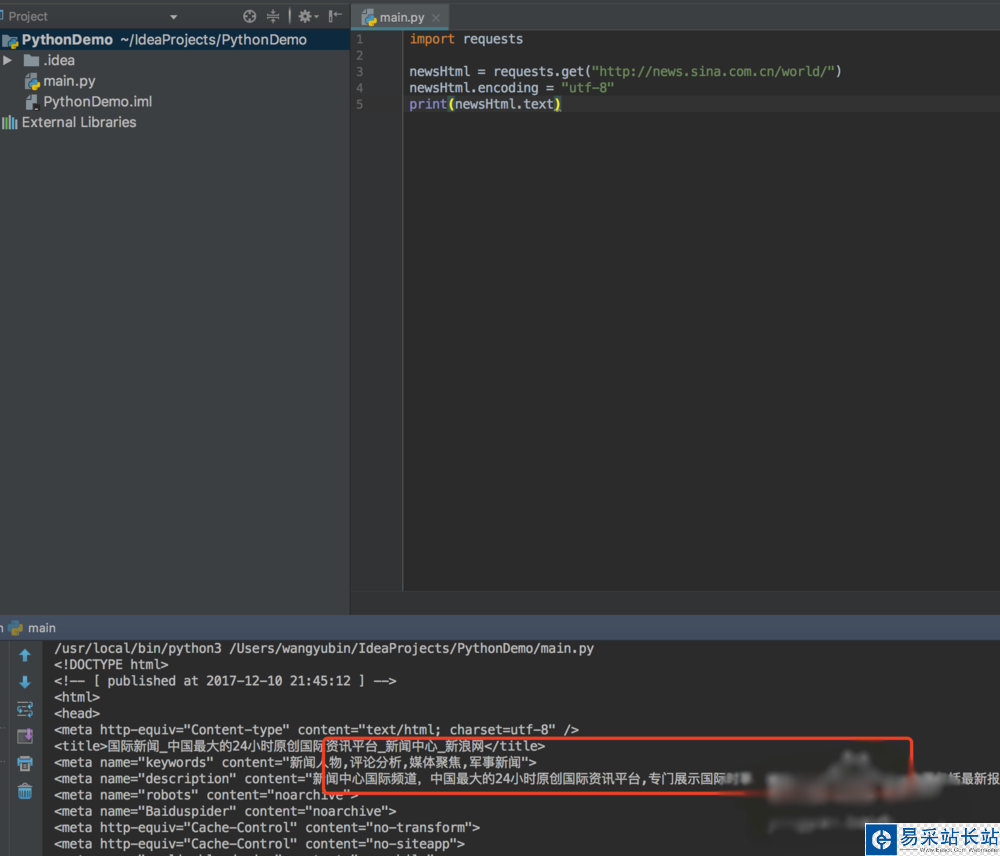
3、安裝好這兩個類庫之后,然后我們就可以先請求數據,查看下新聞的內容,這個時候我們有可能看到的是亂碼
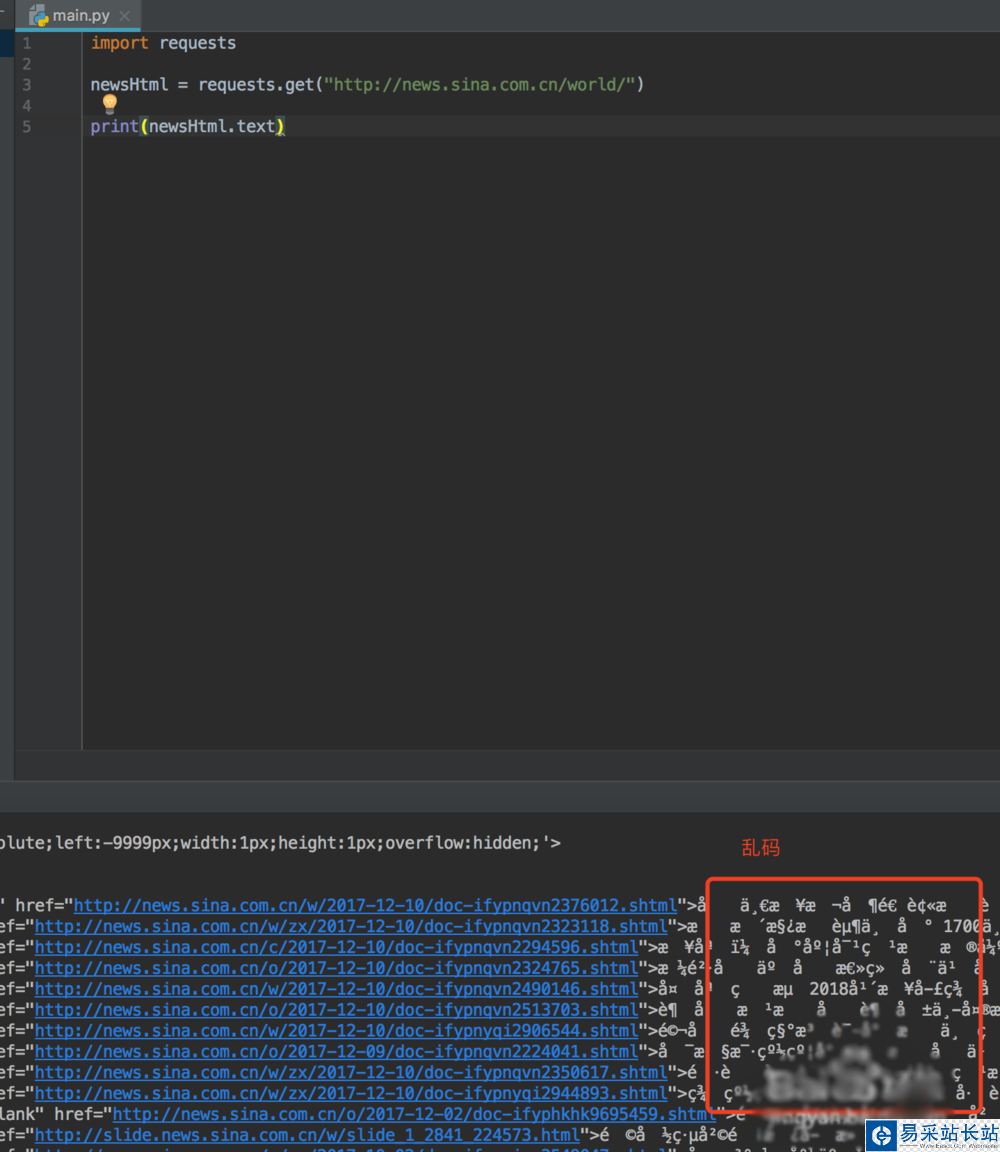
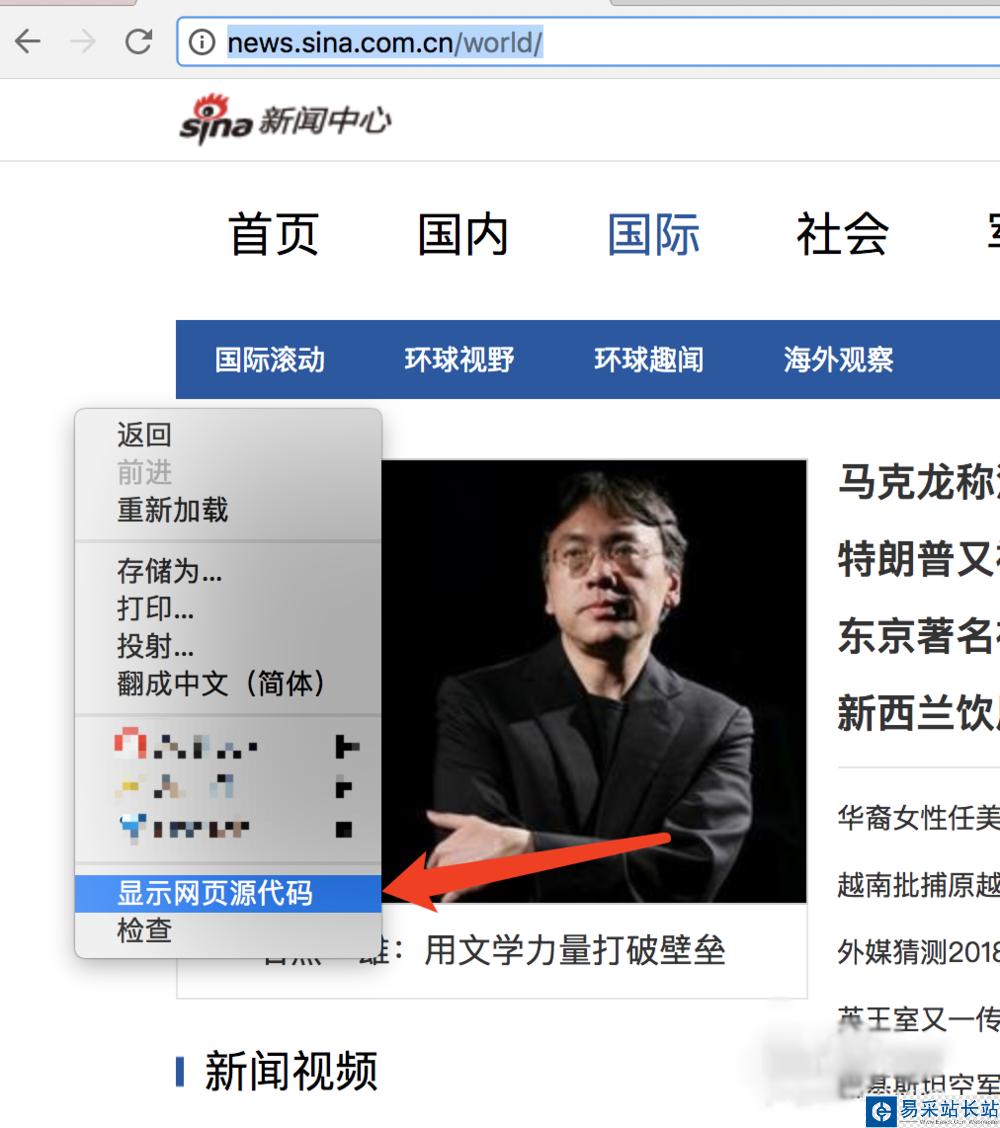
4、怎么處理亂碼呢?我們可以拿瀏覽器打開網頁,右鍵查看網頁源代碼,我們可以看到編碼格式為utf-8
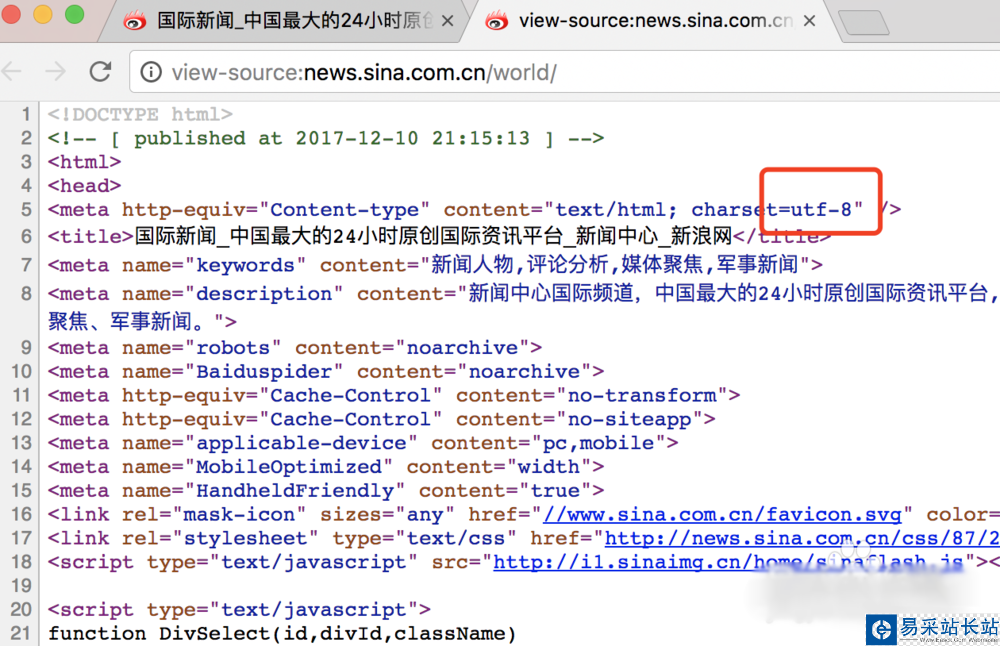
5、然后我們在輸出的時候添加編碼格式,就可以查看到正確編碼的數據了
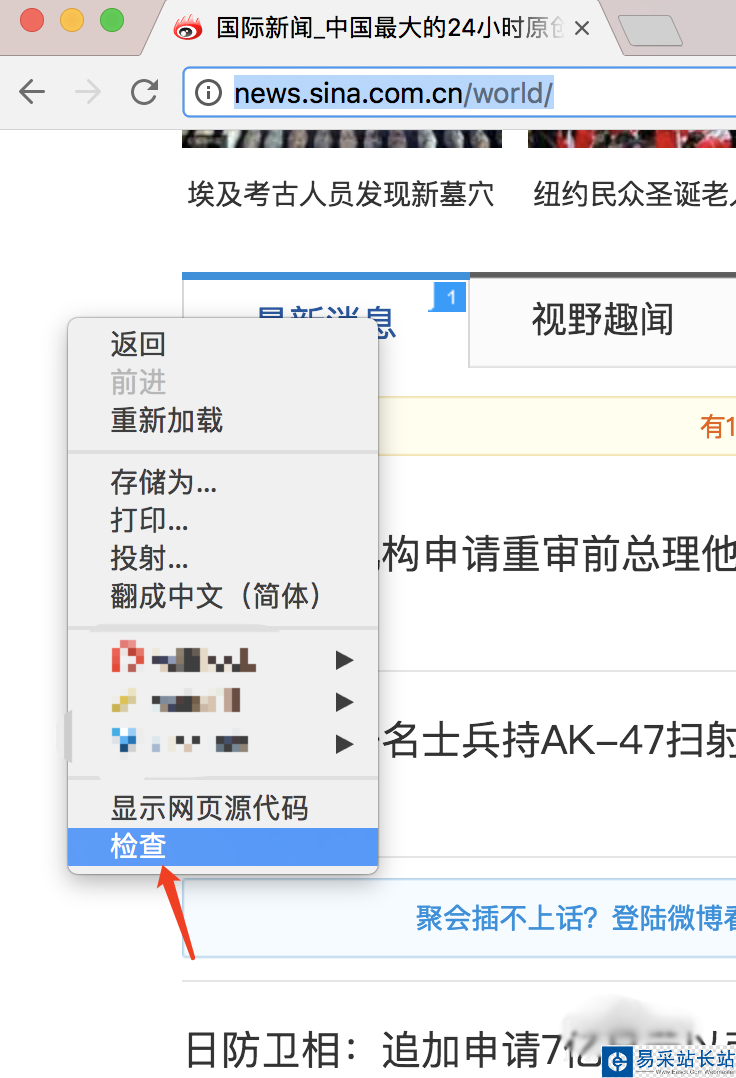
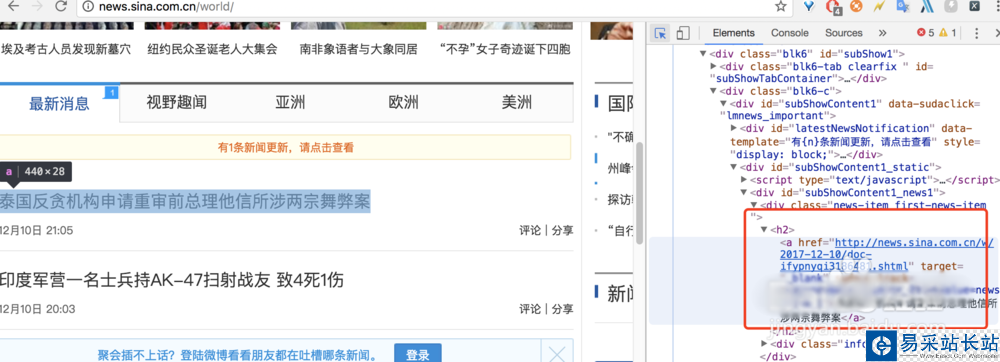
6、拿到數據之后,我們需要先分析數據,看我們想要的數據在哪里,我們打開瀏覽器,右鍵審查,然后按示例圖操作,就可以看到我們新聞所在的標簽,假如是windows系統,選擇開發中工具里面一樣
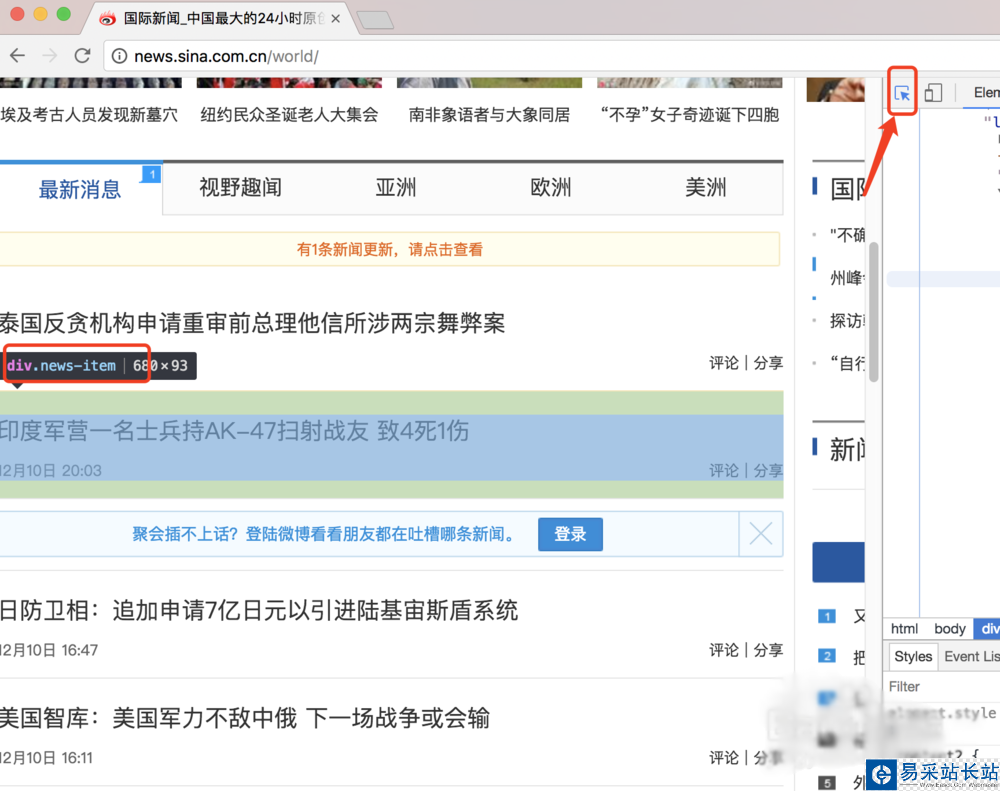
7、我們知道屬于哪個標簽之后,就是用bs4來解析拿到我們想要的數據了
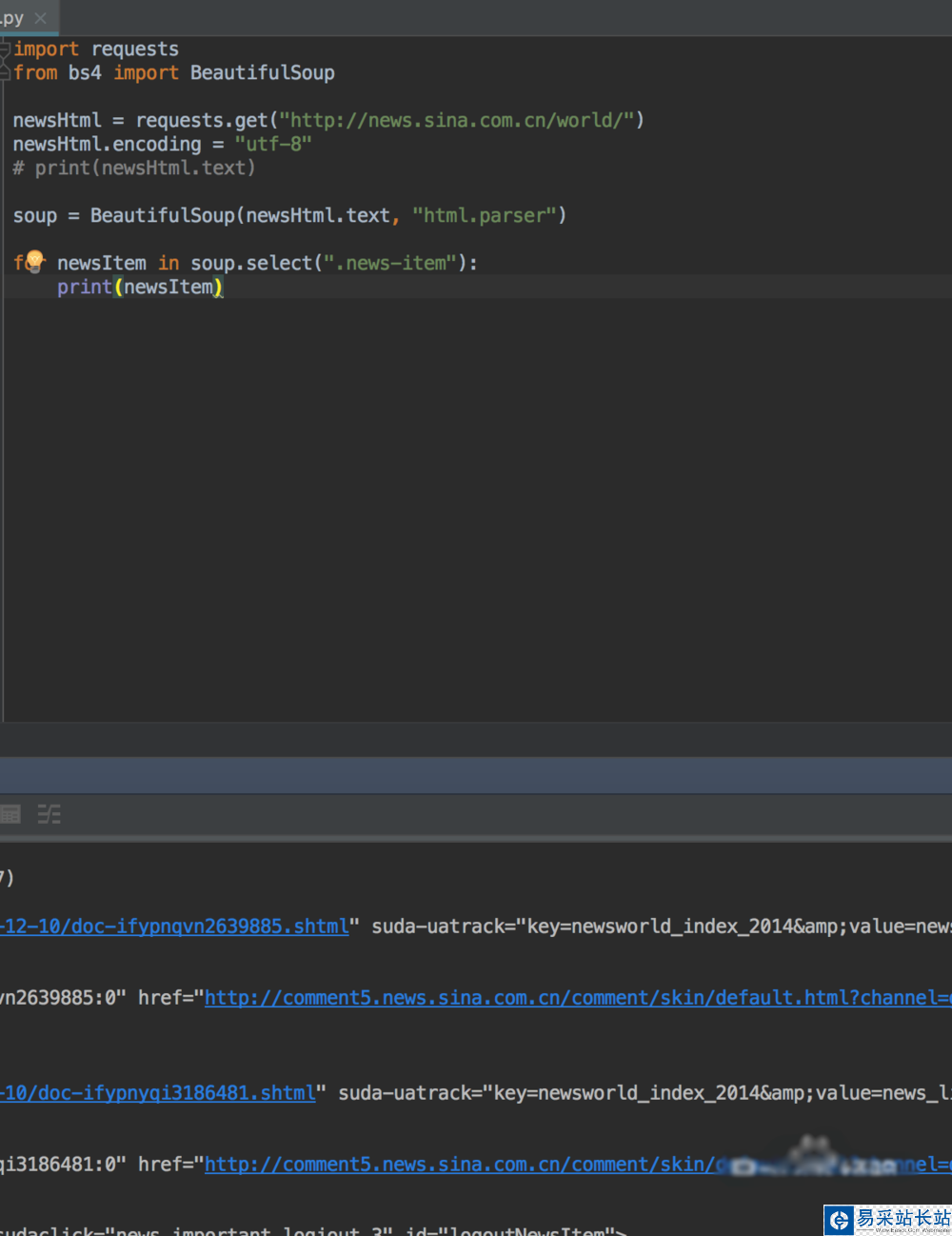
8、我們想要拿到新聞的具體標題,時間,地址,就需要我們在對元素進行深入的解析,我們還是按之前的方法,找到標題所在的標簽
9、然后我們編寫標題時間地址的python程序,就可以爬取出對應的標題內容,時間和地址
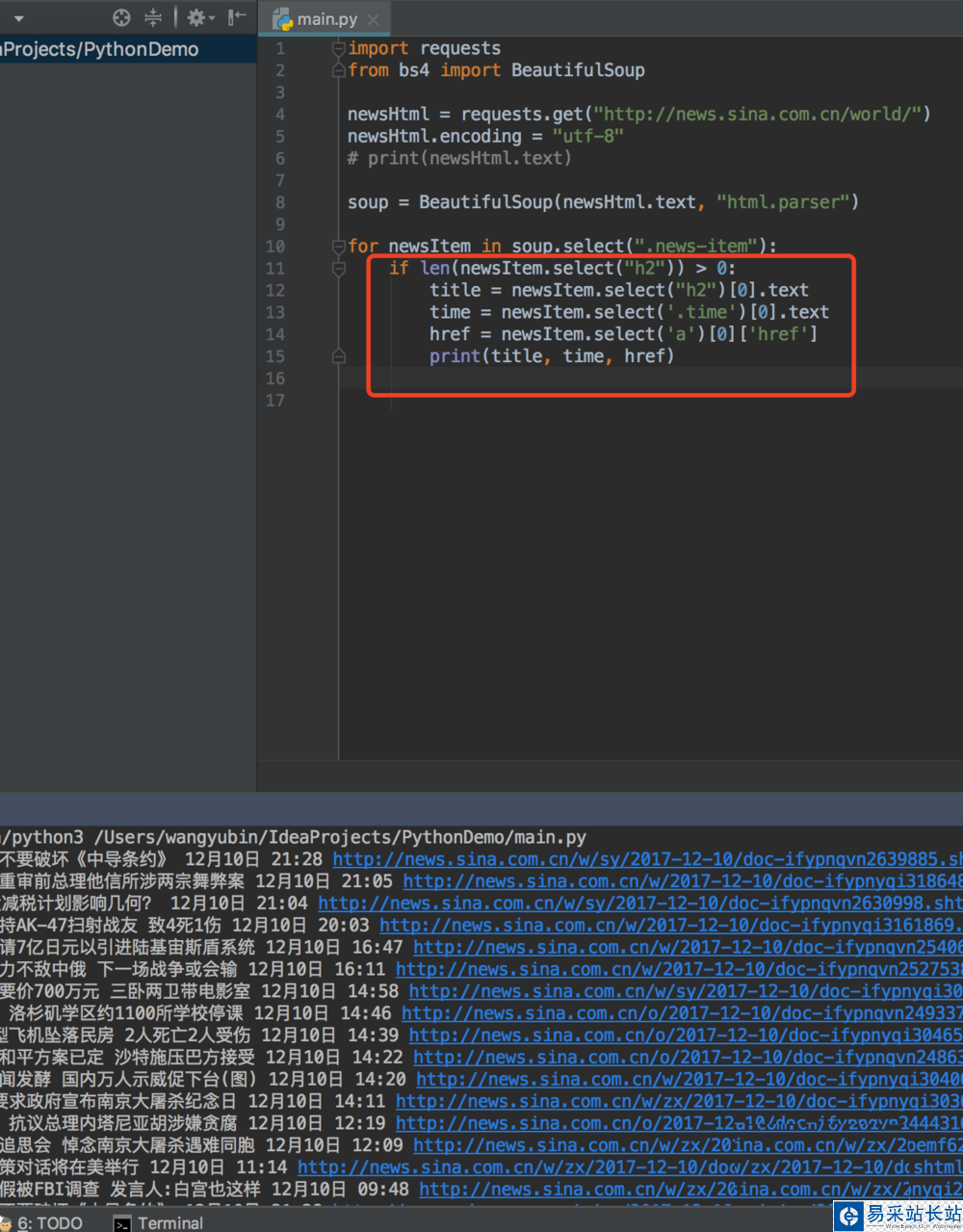
10、簡單的python爬取新聞就講到這里啦
總結:以上就是關于Python爬蟲獲取新浪新聞內容的步驟,感謝大家的的閱讀和對武林站長站的支持。
新聞熱點






疑難解答













