本文實例講述了Python3爬蟲學習之爬蟲利器Beautiful Soup用法。分享給大家供大家參考,具體如下:
爬蟲利器Beautiful Soup
前面一篇說到通過urllib.request模塊可以將網頁當作本地文件來讀取,那么獲得網頁的html代碼后,自然就是要將我們所需要的部分從雜亂的html代碼中分離出來。既然要做數據的查找和提取,當然我們首先想到的應該是正則表達式的方式,而正則表達式書寫的復雜我想大家都有體會,而且Python中的正則表達式和其他語言中的并沒有太大區別,也就不贅述了,所以現在介紹Python中一種比較友好且易用的數據提取方式——Beautiful Soup
照例,先上官方文檔
還有貼心的中文版
Beautiful Soup是一個可以從HTML或XML文件中提取數據的Python庫.它能夠通過你喜歡的轉換器實現慣用的文檔導航,查找,修改文檔的方式.
文檔中的例子其實說的已經比較清楚了,那下面就以爬取簡書首頁文章的標題一段代碼來演示一下:
先來看簡書首頁的源代碼:
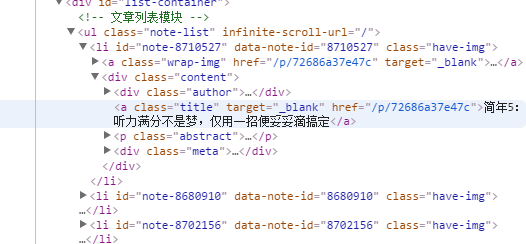
可以發現簡書首頁文章的標題都是在<a/>標簽中,并且class='title',所以,通過
find_all('a', 'title') 便可獲得所有的文章標題,具體實現代碼及結果如下:
# -*- coding:utf-8 -*-from urllib import requestfrom bs4 import BeautifulSoupurl = r'http://www.jianshu.com'# 模擬真實瀏覽器進行訪問headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}page = request.Request(url, headers=headers)page_info = request.urlopen(page).read()page_info = page_info.decode('utf-8')# 將獲取到的內容轉換成BeautifulSoup格式,并將html.parser作為解析器soup = BeautifulSoup(page_info, 'html.parser') # 以格式化的形式打印html# print(soup.prettify())titles = soup.find_all('a', 'title') # 查找所有a標簽中class='title'的語句# 打印查找到的每一個a標簽的stringfor title in titles: print(title.string)
PS:關于解析器
Beautiful Soup支持Python標準庫中的HTML解析器,還支持一些第三方的解析器,下表列出了主要的解析器,以及它們的優缺點:
| 解析器 | 使用方法 | 優勢 | 劣勢 |
|---|---|---|---|
| Python標準庫 | BeautifulSoup(markup, "html.parser") | (1)Python的內置標準庫 (2)執行速度適中 (3)文檔容錯能力強 | Python 2.7.3 or 3.2.2)前 的版本中文檔容錯能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | (1)速度快 (2)文檔容錯能力強 | 需要安裝C語言庫 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml", "xml"]) OR BeautifulSoup(markup, "xml") | (1)速度快 (2)唯一支持XML的解析器 | 需要安裝C語言庫 |
| html5lib | BeautifulSoup(markup, "html5lib") | (1)最好的容錯性 (2)以瀏覽器的方式解析文檔 (3)生成HTML5格式的文檔 | (1)速度慢 (2)不依賴外部擴展 |
新聞熱點






疑難解答













