今天又幫女朋友處理了一下,她的實驗數據,因為python是一年前經常用,最近找工作,用的是c,c++,python的有些東西忘記了,然后就一直催我,說我弄的慢,弄的慢,你自己弄啊,煩不煩啊,逼逼叨叨的,最后還不是我給弄好的?呵呵
好的,數據是這樣的,我截個圖
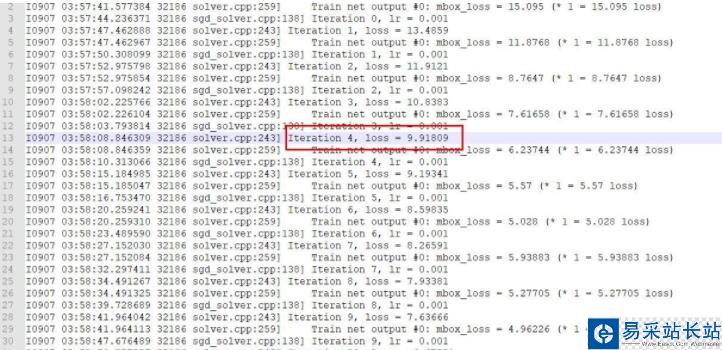
我用紅括號括起來的,就是我所要提取的數據
其中lossstotal.txt是我要提取的原始數據,考慮兩種方法去提取,前期以為所要提取行的數據是有一定規律的,后來發現,并不是,所以,我考慮用正則來提取,經過思考以后,完成了數據的提取,如下午所示,數據變的非常好看
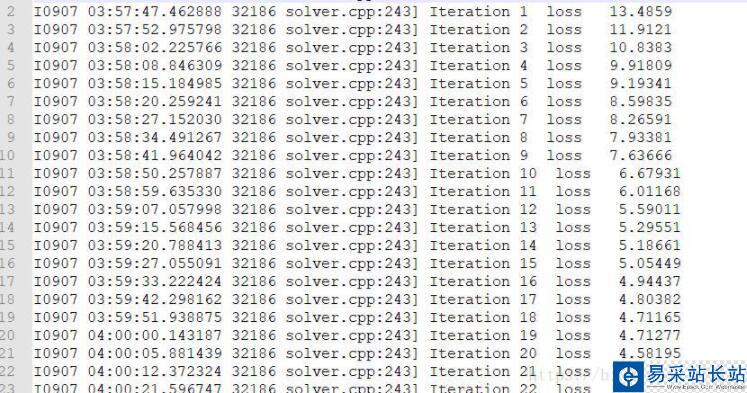
代碼如下:
#coding:utf-8#__author__ ='dell'import ref1=file('losstotal.txt','r')data1=f1.readlines()# print data1f1.close()results = []f2 = open('loss2.txt', 'w')# # 按照特定行提取,發現后面的行并無規律# i = 0# for line in data1:# i+=1# # print line# if((i-1)%3==0):# f2.write(line)# print line# 利用正則表達式for line in data1: data2=line.split() # print data2 for i in data2: n = re.findall(r"Iteration", i) # m=re.findall(r"loss", i) if n: # print line f2.writelines(line)f2.close()f3=file('loss2.txt','r')data3=f3.readlines()# print data1f3.close()f4 = open('loss3.txt', 'w')for line in data3: data4=line.split() # print data2 for i in data4: n = re.findall(r"loss", i) # m=re.findall(r"loss", i) if n: print line f4.writelines(line)f4.close()# 去掉逗號f5=open('loss3.txt','r')data5=f5.read()f5=data5.replace(',',' ')f6=file('lossfinal.txt','w')f6.write(f5)f6.close()# # 去掉等號=f7=open('lossfinal.txt','r')data7=f7.read()f7=data7.replace('=',' ')f8=file('lossfinal.txt','w')f8.write(f7)f8.close() # data3=lin.split() # for j in data3: # m=re.findall(r"loss",i) # if m: # print lin # # m=re.findall(r"sgd_solver.cpp",i) # n=re.findall(r"Iteration",i)我在同樣的目錄下,還建立了
這幾個txt文件,要不然,代碼跑不通的喲。
解釋:我連續用了兩個正則,各自把含有特定字符串的行進行提取,兩個寫一起,發現還是不太會,所以分開寫了,但是結果還是完成的不錯!
以上這篇python提取具有某種特定字符串的行數據方法就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持武林站長站。
新聞熱點






疑難解答













