Python新手編寫腳本處理數據,各種心酸各種語法查找,以此留念!
原始數據格式如下圖所示:
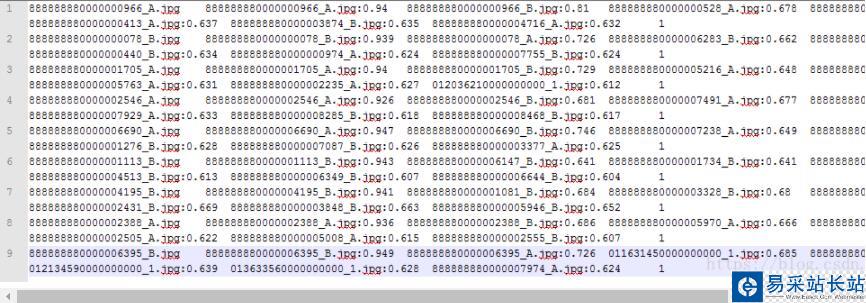
這里是一個人臉測試數據,其中每行第一個為測試圖片編號,后面為Top 7圖片編號及其對應的評分,即與測試圖片的相似度度量結果。我們這里的目的是將每行Top 7對應的評分數據抽取出來,并且將評分第二的數值與一個閾值(這里是0.7)進行比較,超過閾值表示此次測試成功,結果為正樣本,記為1,否則置0。并最終將其保存至另一個文本文件用于作為機器學習模型的訓練樣本數據。
Python腳本處理后的文件格式如下所示:

對應的Python代碼如下所示,附有小白詳細注釋。
# -*- coding: cp936 -*-import reimport linecachefilename = 'face_test_data.txt' with open(filename, 'r') as f: line = f.readline() while line: eachline = line.split()###按行讀取文本文件 #print eachline 返回一個列表,以空格作為元素拆分標識 #print line 返回的是一整行數據,相當于一個字符串元素 count = len(eachline)#返回列表長度,即列表元素數目 n = 0 element = []#初始化空列表用于存儲所需評分數據 while n < count: elem_index = eachline[n:n+1] #類型為列表 #print elem_index, len(elem_index[0]) #print elem_index 返回類型為列表 if len(elem_index[0]) > 24: element.append(elem_index[0][25:]) #element = [qiege(elem_index[n]) for elem_index in eachline] n=n+1 #print element[1] #概率數值列表 if element[1] >= '0.7': element.append(1) #print '1' else: element.append(0) #print '0' #生成每行末尾有/t文件 ''' file = open('preprocess.txt', 'a') for i in range(len(element)): file.write(str(element[i])+'/t') file.write('/n') file.close() ''' #生成每行末尾無/t文件,可直接用于np.loadtxt()讀取文本生成矩陣數據 file = open('_preprocess.txt', 'a') for i in range(len(element)-1): file.write(str(element[i])+'/t') file.write(str(element[-1])+'/n') #file.write('/n') file.close() line = f.readline()以上這篇Python 文本文件內容批量抽取實例就是小編分享給大家的全部內容了,希望能給大家一個參考,也希望大家多多支持武林站長站。
新聞熱點






疑難解答













