我們都見識過requests庫在靜態網頁的爬取上展現的威力,我們日常見得最多的為get和post請求,他們最大的區別在于安全性上:
1、GET是通過URL方式請求,可以直接看到,明文傳輸。
2、POST是通過請求header請求,可以開發者工具或者抓包可以看到,同樣也是明文的。 3.GET請求會保存在瀏覽器歷史紀錄中,還可能會保存在Web的日志中。
兩者用法上也有顯著差異(援引自知乎):
1、GET用于從服務器端獲取數據,包括靜態資源(HTML|JS|CSS|Image等等)、動態數據展示(列表數據、詳情數據等等)。
2、POST用于向服務器提交數據,比如增刪改數據,提交一個表單新建一個用戶、或修改一個用戶等。
對于Post請求,我們可以通過瀏覽器開發者工具或者其他外部工具來進行抓包,得到請求的URL、請求頭(request headers)以及請求的表單data信息,這三樣恰恰是我們用requests模擬post請求時需要的,典型的寫法如下:
response=requests.post(url=url,headers=headers,data=data_search)
由于post請求很多時候是配合Ajax(異步加載)技術一起使用的,我們抓包時,可以直接選擇XHR(XmlHttpRequest)-ajax的一種對象,幫助我們濾掉其他的一些html、css、js類文件,如下圖所示(截取自Chrome):
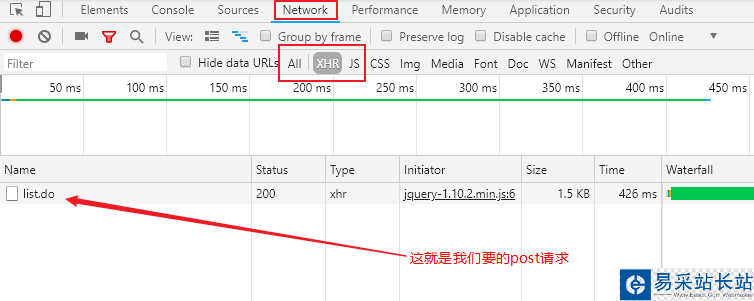
雙擊點開,就可以在頁面右邊的Headers頁下看到General、Response Headers、Request Headers、Form Data幾個模塊,
其中General模塊能看到請求的方法和請求的URL以及服務器返回的狀態碼(200(成功) 服務器已成功處理了請求。通常,這表示服務器提供了請求的網頁。)

而Response Headers部分,可以看到緩存控制、服務器類型、返回內容格式、有效期等參數(筆者截圖所示,返回的為json文件):

Request Header模塊是非常重要的,可以有效地將我們的爬取行為模擬成瀏覽器行為,應對常規的服務器反爬機制:
其中Content-Type、Cookie以及User-Agent字段較為重要,需要我們構造出來(其他字段大多數時候,不是必須)

由于Cookie字段記錄了用戶的登陸信息,每次都不同,且同一個cookie存在一定有效期,當我們結合Selenium來組合爬取頁面信息時,可以通過selenium完成網頁的登陸校驗,然后利用selenium提取出cookie,再轉換為瀏覽器能識別的cookie格式,通常代碼如下所示:
cookies = driver.get_cookies() #利用selenium原生方法得到cookiesret=''for cookie in cookies: cookie_name=cookie['name'] cookie_value=cookie['value'] ret=ret+cookie_name+'='+cookie_value+';' #ret即為最終的cookie,各cookie以“;”相隔開
新聞熱點






疑難解答













