前言
Python文件默認的編碼格式是ascii ,無法識別漢字,因為ascii碼中沒有中文。
所以py文件中要寫中文字符時,一般在開頭加 # -*- coding: utf-8 -*- 或者 #coding=utf-8。
這是指定一種編碼格式,意味著用該編碼存儲中文字符(也可以是gbk、gb2312等)。
關于測試的幾點注意 --------------------------------------------
注1:代碼中有中文,就要在頭部指定編碼方式,如果用編輯器寫代碼,還要注意IDE的文件存儲編碼格式(一般在setting)
注2:python3.x的源碼文件默認使用utf-8編碼,可以解析中文,開頭不指定也行,但為了規范和避免一些意想不到的問題,都指定一下為好
注3:linux交互式命令(左)和py文件(右)的運行結果會有不同:
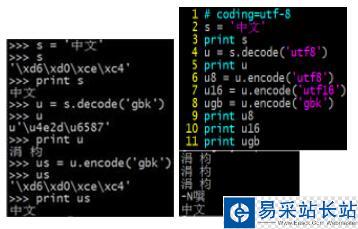
左圖,因為我cmd設置了gbk編碼格式,所以u是s用gbk解碼后的unicode對象,配套的解編碼才能使原中文字符在print下正常顯示,所以再用gbk編碼;右圖,py文件指定了utf8編碼,所以u是s用utf8解碼后的unicode對象(其他方式會運行錯誤),而且想要在屏幕上打印出中文,還須encode成cmd設置的編碼(其他方式顯示亂碼)。
注4:測試中文字符的顯示和匹配時,最好用py文件寫,否則遇到兩邊不一樣的情況就會感到十分坑爹
----------------------------------------------------------------
下面實驗是基于python2.7和linux系統,不測試windows控制臺和windows下的IDE;
下面實驗是關于為了正常顯示中文和正則匹配中文的轉碼測試。
(一)python的str和中文字符串
簡單理解,編碼意味著 unicode -> ch-str,解碼意味著 ch-str -> unicode,
關于print顯示中文。舉個例子,用gb18030和utf-8編碼的內容相同的兩份文檔測試:
#coding=utf-8import syswith open('ch_input_gbk', 'r') as f1, open('ch_input_utf', 'r') as f2: for l1 in f1: lines = l1.strip().split('/t') # lines是list, 通過打印它可以看看str不同編碼的內容 sent = lines[0] # sent是ch-str print lines, sent for l2 in f2: lines = l2.strip().split('/t') sent = lines[0] print lines, sent print sent.decode('utf8').encode('gbk') #print str(sent).decode('string_escape').decode('utf8').encode('gbk')輸出:
['/xd3/xc4/xc8/xcb/xd6/xf1/xc9/xa3/xd4/xb0'] 幽人竹桑園['/xb9/xe9/xce/xd4/xbc/xc5/xce/xde/xd0/xfa'] 歸臥寂無喧['/xce/xef/xc7/xe9/xbd/xf1/xd2/xd1/xbc/xfb'] 物情今已見['/xb4/xd3/xb4/xcb/xd3/xfb/xce/xde/xd1/xd4'] 從此欲無言['/xe5/xb9/xbd/xe4/xba/xba/xe7/xab/xb9/xe6/xa1/x91/xe5/x9b/xad'] 騫戒漢绔規鍥幽人竹桑園['/xe5/xbd/x92/xe5/x8d/xa7/xe5/xaf/x82/xe6/x97/xa0/xe5/x96/xa7'] 褰掑崸瀵傛棤鍠歸臥寂無喧['/xe7/x89/xa9/xe6/x83/x85/xe4/xbb/x8a/xe5/xb7/xb2/xe8/xa7/x81'] 鐗╂儏浠婂凡瑙物情今已見['/xe4/xbb/x8e/xe6/xad/xa4/xe6/xac/xb2/xe6/x97/xa0/xe8/xa8/x80'] 浠庢嬈叉棤璦從此欲無言
新聞熱點






疑難解答













