對(duì)于大多數(shù)朋友而言,爬蟲(chóng)絕對(duì)是學(xué)習(xí) python 的最好的起手和入門(mén)方式。因?yàn)榕老x(chóng)思維模式固定,編程模式也相對(duì)簡(jiǎn)單,一般在細(xì)節(jié)處理上積累一些經(jīng)驗(yàn)都可以成功入門(mén)。本文想針對(duì)某一網(wǎng)頁(yè)對(duì) python 基礎(chǔ)爬蟲(chóng)的兩大解析庫(kù)( BeautifulSoup 和 lxml )和幾種信息提取實(shí)現(xiàn)方法進(jìn)行分析,以開(kāi) python 爬蟲(chóng)之初見(jiàn)。
基礎(chǔ)爬蟲(chóng)的固定模式
筆者這里所談的基礎(chǔ)爬蟲(chóng),指的是不需要處理像異步加載、驗(yàn)證碼、代理等高階爬蟲(chóng)技術(shù)的爬蟲(chóng)方法。一般而言,基礎(chǔ)爬蟲(chóng)的兩大請(qǐng)求庫(kù) urllib 和 requests 中 requests 通常為大多數(shù)人所鐘愛(ài),當(dāng)然 urllib 也功能齊全。兩大解析庫(kù) BeautifulSoup 因其強(qiáng)大的 HTML 文檔解析功能而備受青睞,另一款解析庫(kù) lxml 在搭配 xpath 表達(dá)式的基礎(chǔ)上也效率提高。就基礎(chǔ)爬蟲(chóng)來(lái)說(shuō),兩大請(qǐng)求庫(kù)和兩大解析庫(kù)的組合方式可以依個(gè)人偏好來(lái)選擇。
筆者喜歡用的爬蟲(chóng)組合工具是:
requests + BeautifulSoup requests + lxml同一網(wǎng)頁(yè)爬蟲(chóng)的四種實(shí)現(xiàn)方式
筆者以騰訊新聞首頁(yè)的新聞信息抓取為例。
首頁(yè)外觀如下:
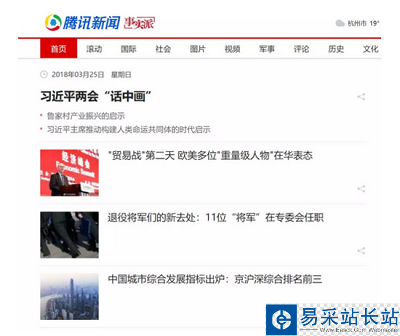
比如說(shuō)我們想抓取每個(gè)新聞的標(biāo)題和鏈接,并將其組合為一個(gè)字典的結(jié)構(gòu)打印出來(lái)。首先查看 HTML 源碼確定新聞標(biāo)題信息組織形式。
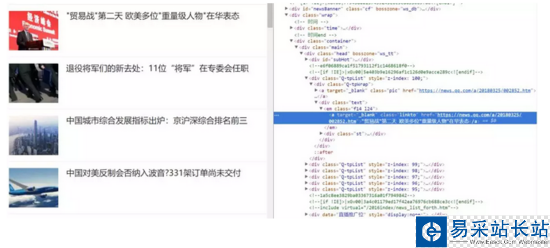
可以目標(biāo)信息存在于 em 標(biāo)簽下 a 標(biāo)簽內(nèi)的文本和 href 屬性中。可直接利用 requests 庫(kù)構(gòu)造請(qǐng)求,并用 BeautifulSoup 或者 lxml 進(jìn)行解析。
方式一: requests + BeautifulSoup + select css選擇器
# select method import requests from bs4 import BeautifulSoup headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'} url = 'http://news.qq.com/' Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml') em = Soup.select('em[class="f14 l24"] a') for i in em: title = i.get_text() link = i['href'] print({'標(biāo)題': title, '鏈接': link })很常規(guī)的處理方式,抓取效果如下:

方式二: requests + BeautifulSoup + find_all 進(jìn)行信息提取
# find_all method import requests from bs4 import BeautifulSoup headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'} url = 'http://news.qq.com/' Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml') em = Soup.find_all('em', attrs={'class': 'f14 l24'})for i in em: title = i.a.get_text() link = i.a['href'] print({'標(biāo)題': title, '鏈接': link })
新聞熱點(diǎn)






疑難解答
圖片精選
網(wǎng)友關(guān)注













