本文實例講述了Python使用爬蟲爬取靜態網頁圖片的方法。分享給大家供大家參考,具體如下:
爬蟲理論基礎
其實爬蟲沒有大家想象的那么復雜,有時候也就是幾行代碼的事兒,千萬不要把自己嚇倒了。這篇就清晰地講解一下利用Python爬蟲的理論基礎。
首先說明爬蟲分為三個步驟,也就需要用到三個工具。
① 利用網頁下載器將網頁的源碼等資源下載。
② 利用URL管理器管理下載下來的URL
③ 利用網頁解析器解析需要的URL,進而進行匹配。
網頁下載器
網頁下載器常用的有兩個。一個是Python自帶的urllib2模塊;另一個是第三方控件requests。選用哪個其實差異不大,下一篇將會進行實踐操作舉例。
URL管理器
url管理器有三大類。
① 內存:以set形式存儲在內存中
② 存儲在關系型數據庫mysql等
③ 緩存數據庫redis中
網頁解析器
網頁解析器一共有四類:
1.正則表達式,不過對于太復雜的匹配就會有些難度,屬于模糊匹配。
2.html.parser,這是python自帶的解析工具。
3.Beautiful Soup,一種第三方控件,顧名思義,美味的湯,用起來確實很方便,很強大。
4.lxml(apt.xml),第三方控件。
以上的這些全部屬于結構化解析(DOM樹)
什么式結構化解析(DOM)?
Document Object Model(DOM)是一種樹的形式。
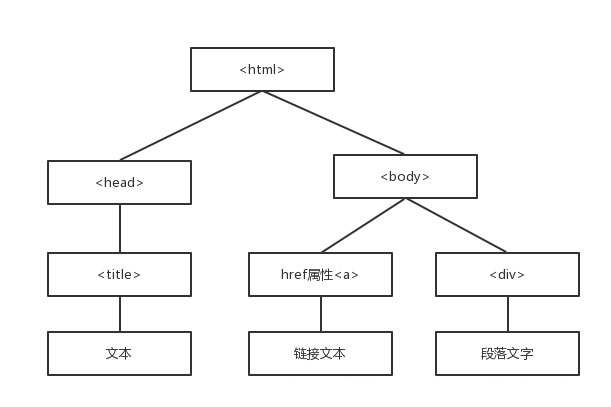
Beautiful Soup的語法
html網頁—>創建BeautifulSoup對象—>搜索節點 find_all()/find()—>訪問節點,名稱,屬性,文字等……
Beautiful Soup官方文檔
實現代碼
說過了理論基礎,那么現在就來實踐一個,要爬取一個靜態網頁的所有圖片。
這里使用的網頁下載器是python自帶的urllib2,然后利用正則表達式匹配,輸出結果。
以下為源碼:
//引入小需要用到的模塊import urllib2import redef main(): //利用urllib2的urlopen方法,下載當前url的網頁內容 req = urllib2.urlopen('http://www.imooc.com/course/list') //將網頁內容存儲到buf變量中 buf = req.read() //將buf中的所有內容與需要匹配的url進行比對。這里的正則表達式是根據靜態網頁的源碼得出的,查看靜態網頁源碼開啟開發者模式,按F12即可。然后確定圖片塊,查看對應源碼內容,找出規律,編寫正則表達式。 listurl = re.findall(r'src=.+/.jpg',buf) i = 0 //將結果循環寫入文件 for url in listurl: f = open(str(i)+'.jpg','w') req = urllib2.urlopen(url[5:]) buf1 = req.read() f.write(buf1) i+=1if __name__ == '__main__': main()至此一個靜態網頁的圖片爬蟲就完成了,下面來看下效果。
這是靜態網頁:
新聞熱點






疑難解答













