問(wèn)題描述:
我們?cè)诰W(wǎng)上下載或者復(fù)制別人代碼的時(shí)候經(jīng)常會(huì)遇到下載的代碼中包含行數(shù)標(biāo)簽的情況。如下圖:
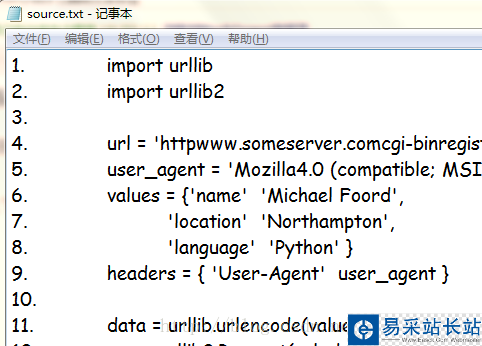
這些代碼中包含著行數(shù)如1.,2.等,如果我們想直接運(yùn)行或者copy代碼需要自己手動(dòng)的刪除這些標(biāo)簽。既然學(xué)了python,我們寫(xiě)一段腳本來(lái)處理它吧。
思路分析:
首先,我們逐行的讀取文本。
利用正則表達(dá)式,可以順利地匹配出所有的這些標(biāo)簽以及后面跟隨的“/t”,正則表達(dá)式為:“/d+./t”。
接著我們將匹配的結(jié)果在這一行中刪除它,使用string模塊的replace方法,將匹配的結(jié)果用‘'代替。
最后,我們保存每次刪除了行數(shù)標(biāo)簽的結(jié)果行,然后將這些行寫(xiě)入原文本。注意,以w的方式打開(kāi)文本會(huì)刪除原文本內(nèi)容。
代碼:
# -*- coding:utf-8 -*- import re import os import sys reload(sys) sys.setdefaultencoding('utf-8') ls = os.linesep label_regex = r'/d+./t' content = [] for line in open('source.txt', 'r'): mm = re.search(label_regex, line) if mm: mm = mm.group() content.append(line.replace(mm, '').rstrip()) else: break f = open('source.txt', 'w') f.writelines(['%s%s' % (x,ls) for x in content]) 結(jié)果:
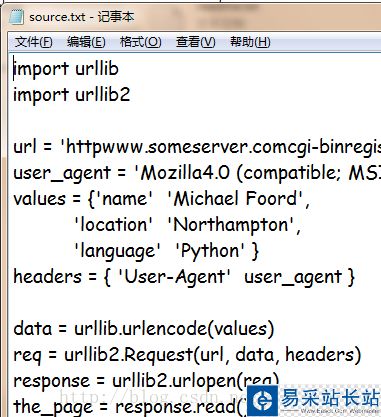
以上就是本文的全部?jī)?nèi)容,希望對(duì)大家的學(xué)習(xí)有所幫助,也希望大家多多支持武林站長(zhǎng)站。
新聞熱點(diǎn)






疑難解答
圖片精選













