最近在學(xué)爬蟲(chóng)時(shí)發(fā)現(xiàn)許多網(wǎng)站都有自己的反爬蟲(chóng)機(jī)制,這讓我們沒(méi)法直接對(duì)想要的數(shù)據(jù)進(jìn)行爬取,于是了解這種反爬蟲(chóng)機(jī)制就會(huì)幫助我們找到解決方法。
常見(jiàn)的反爬蟲(chóng)機(jī)制有判別身份和IP限制兩種,下面我們將一一來(lái)進(jìn)行介紹。
(一) 判別身份
首先我們看一個(gè)例子,看看到底什么時(shí)反爬蟲(chóng)。
我們還是以 豆瓣電影榜top250(https://movie.douban.com/top250) 為例。`
import requests# 豆瓣電影榜top250的網(wǎng)址url = 'https://movie.douban.com/top250'# 請(qǐng)求與網(wǎng)站的連接res = requests.get(url)# 打印獲取的文本print(res.text)
這是段簡(jiǎn)單的請(qǐng)求與網(wǎng)站連接并打印獲取數(shù)據(jù)的代碼,我們來(lái)看看它的運(yùn)行結(jié)果。

我們可以發(fā)現(xiàn)我們什么數(shù)據(jù)都沒(méi)有獲取到,這就是由于這個(gè)網(wǎng)站有它的身份識(shí)別功能,把我們識(shí)別為了爬蟲(chóng),拒絕為我們提供數(shù)據(jù)。不管是瀏覽器還是爬蟲(chóng)訪問(wèn)網(wǎng)站時(shí)都會(huì)帶上一些信息用于身份識(shí)別。而這些信息都被存儲(chǔ)在一個(gè)叫請(qǐng)求頭(request headers) 的地方。而這個(gè)請(qǐng)求頭中我們只需要了解其中的一個(gè)叫user-agent(用戶(hù)代理) 的就可以了。user-agent里包含了操作系統(tǒng)、瀏覽器類(lèi)型、版本等信息,通過(guò)修改它我們就能成功地偽裝成瀏覽器。
下面我們來(lái)看怎么找這個(gè)user-agent吧。
首先得打開(kāi)瀏覽器,隨便打開(kāi)一個(gè)網(wǎng)站,再打開(kāi)開(kāi)發(fā)者工具。
再點(diǎn)擊network標(biāo)簽,接著點(diǎn)第一個(gè)請(qǐng)求,再找到Request Headers,最后找到user-agent字段。(有時(shí)候可能點(diǎn)擊network標(biāo)簽后是空白得,這時(shí)候刷新下網(wǎng)頁(yè)就好啦!)
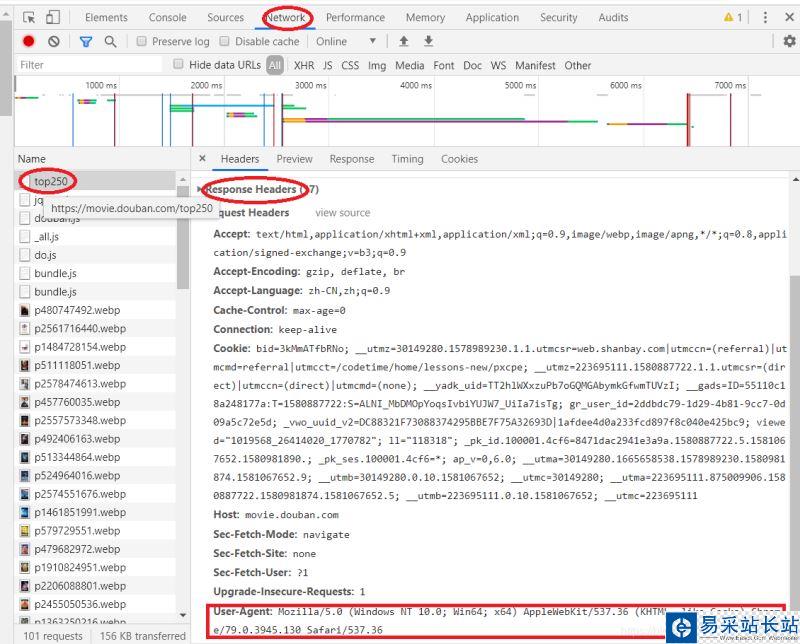
找到請(qǐng)求頭后,我們只需要把他放進(jìn)一個(gè)字典里就好啦,具體操作見(jiàn)下面代碼。
import requests# 復(fù)制剛才獲取得請(qǐng)求頭headers = { 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}# 豆瓣電影榜top250的網(wǎng)址url = 'https://movie.douban.com/top250'# 請(qǐng)求與網(wǎng)站的連接res = requests.get(url, headers=headers)# 打印獲取的文本print(res.text)現(xiàn)在我們?cè)賮?lái)看部分輸出結(jié)果。
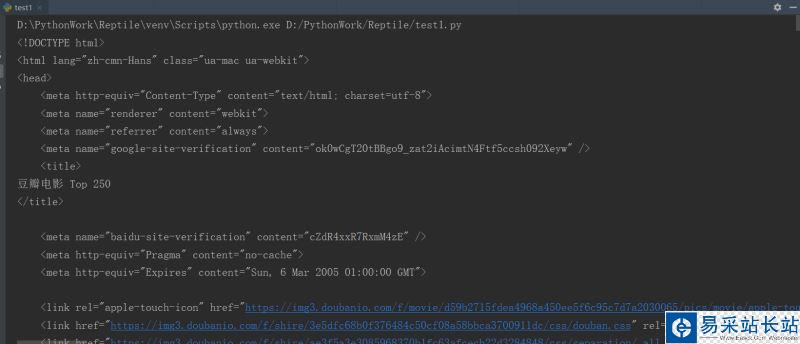
我們可以發(fā)現(xiàn)已經(jīng)將該網(wǎng)站的HTML文件全部爬取到了,至此第一種方法就將完成了。下面我們來(lái)看第二種方法。
(二) IP限制
IP(Internet Protocol) 全稱(chēng)互聯(lián)網(wǎng)協(xié)議地址,意思是分配給用戶(hù)上網(wǎng)使用的網(wǎng)際協(xié)議的設(shè)備的數(shù)字標(biāo)簽。它就像我們身份證號(hào)一樣,只要知道你的身份證號(hào)就能查出你是哪個(gè)人。
新聞熱點(diǎn)






疑難解答
圖片精選













