首頁| 新聞| 娛樂| 游戲| 科普| 文學| 編程| 系統| 數據庫| 建站| 學院| 產品| 網管| 維修| 辦公| 熱點
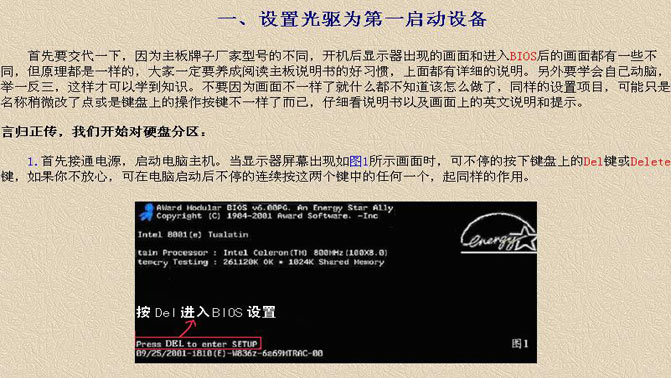
修改BIOS啟動項 圖文教程
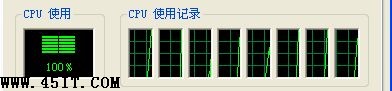
cpu使用率高的解決辦法
打印機不能打印怎么辦?【原因與解決辦法】
知性、優雅,讓人賞心悅目
校園甜美的背影,洋溢著青春爛漫的回憶
蕪湖有個“松鼠小鎮”
小滿:小得盈滿,一切剛剛好!
一串串晶瑩剔透的葡萄,像一顆顆寶石掛在藤
正宗老北京脆皮烤鴨
人逢知己千杯少,喝酒搞笑圖集
搞笑試卷,學生惡搞答題
新聞熱點
疑難解答
圖片精選
可穿戴手勢識別控制器
Dictionary數據類型在Darwin視頻服
如何理解“卷積運算”, 在0-t時刻
網友關注