一、簡介
有的時候,我們需要分析日志來排查錯誤,但是日志文件特別大,打開肯定是很慢的,也是沒法接受的,我們需要的是快速定位錯誤出現的位置,并定向取出錯誤信息。
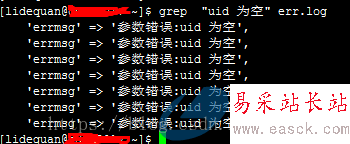
快速定位某個字符串在某文件中出現的行數,可以使用 linux中grep命令
默認情況,grep命令只會輸出匹配的字符串所在的行,如下:
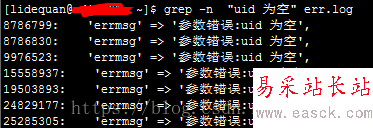
要想同時輸出行號,可以指定參數-n,關于-n參數描述如下:
-n, --line-number print line number with output lines
現在,我們已經確定要查詢的錯誤所在行數,就可以通過 tail和head或是sed命令輸出特定的行
1、利用tail和head來輸出特定的行
通過tail –help ,我們可以看到tail 默認顯示最后10行,通過 -n參數可以指定從第n行數開始顯示,或是顯示最后n行,如下:
-n, --lines=K output the last K lines, instead of the last 10; or use -n +K to output lines starting with the Kth
也就是說:
tail -n 5 f.txt //顯示f.txt最后5行tail -n +5 f.txt //從第5行開始,顯示f.txt
通過head –help ,我們可以看到head默認顯示最前10行,通過 -n參數可以指定從倒數第n行開始,顯示前面的所有,或是顯示最前面的n行
-n, --lines=[-]K print the first K lines instead of the first 10; with the leading `-', print all but the last
也就是說:
head -n 5 f.txt //顯示f.txt最前面5行tail -n -5 f.txt //從倒數第5行開始,顯示前面的所有內容
比如,在上面我們定位到了8786830行,那么,我們就可以利用tail和head,查其附近的內容(即錯誤前20行,后10行內容),如下:
tail -n +8786810 err.log |head -n 30
2、利用sed來輸出特定的行
通過sed來查看指定的行,就比較簡單,格式如下:
sed -n "n1,n2p" f.txt //查看f.txt n1行到n2行之間的內容
比如,在上面我們定位到了8786830行,那么,我們就可以利用sed,查其附近的內容(即錯誤前20行,后10行內容),如下:
sed -n "8786810,8786840p" err.log
補充:shell 字符串出現的行數
1 查詢字符串所在的行號
grep -n "xxx" str.txt # -n 打印字符 “xxx” 在文件 “str.txt” 所在的行數前綴
示例:
str.txt
xxx
yyy
zzz
xxx
輸入查找命令: grep -n "xxx" str.txt
新聞熱點






疑難解答