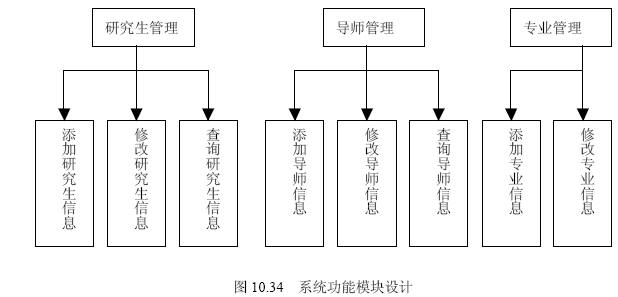
sql server
想必每一位sql server開發人員都有過類似的經歷,在對數據庫進行查詢或統計的時候不時地會碰到由于表中存在重復的記錄而導致查詢和統計結果不準確。解決該問題的辦法就是將這些重復的記錄刪除,只保留其中的一條。
在sql server中除了對擁有十幾條記錄的表進行人工刪除外,實現刪除重復記錄一般都是寫一段代碼,用游標的方法一行一行檢查,刪除重復的記錄。因為這種方法需要對整個表進行遍歷,所以對于表中的記錄數不是很大的時候還是可行的,如果一張表的數據達到上百萬條,用游標的方法來刪除簡直是個噩夢,因為它會執行相當長的一段時間。
四板斧——輕松消除重復記錄
殊不知在sql server中有一種更為簡單的方法,它不需要用游標,只要寫一句簡單插入語句就能實現刪除重復記錄的功能。為了能清楚地表述,我們首先假設存在一個產品信息表products,其表結構如下:
create table products (
productid int,
productname nvarchar (40),
unit char(2),
unitprice money
)
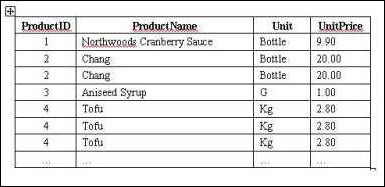
表中的數據如圖1:
圖表
圖1中可以看出,產品chang和tofu的記錄在產品信息表中存在重復。現在要刪除這些重復的記錄,只保留其中的一條。步驟如下:
第一板斧——建立一張具有相同結構的臨時表
create table products_temp (
productid int,
productname nvarchar (40),
unit char(2),
unitprice money
)
第二板斧——為該表加上索引,并使其忽略重復的值
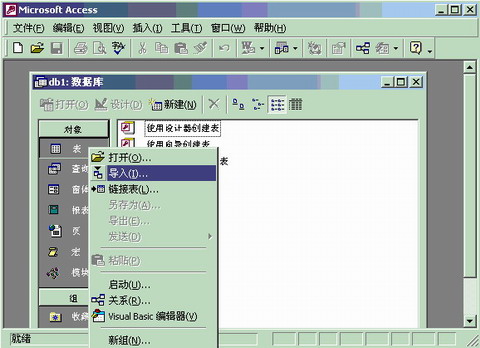
方法是在企業管理器中找到上面建立的臨時表products _temp,單擊鼠標右鍵,選擇所有任務,選擇管理索引,選擇新建。如圖2所示。
按照圖2中圈出來的地方設置索引選項。
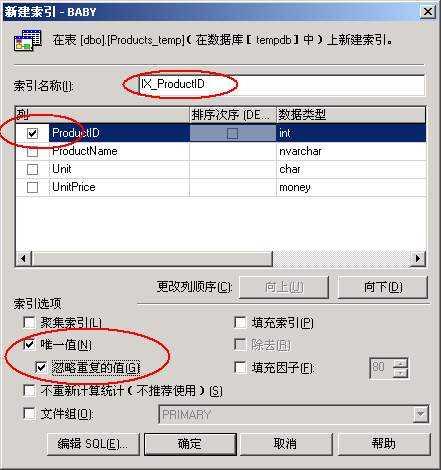
圖2
第三板斧——拷貝產品信息到臨時表
insert into products_temp select * from products
此時sql server會返回如下提示:
服務器: 消息 3604,級別 16,狀態 1,行 1
已忽略重復的鍵。
它表明在產品信息臨時表products_temp中不會有重復的行出現。
第四板斧——將新的數據導入原表
將原產品信息表products清空,并將臨時表products_temp中數據導入,最后刪除臨時表products_temp。
delete products
insert into products select * from products_temp
drop table products_temp
這樣就完成了對表中重復記錄的刪除。無論表有多大,它的執行速度都是相當快的,而且因為幾乎不用寫語句,所以它也是很安全的。
小提示:上述方法中刪除重復記錄取決于創建唯一索引時選擇的字段,在實際的操作過程中讀者務必首先確認創建的唯一索引字段是否正確,以免將有用的數據刪除。
oracle
在oracle中,可以通過唯一rowid實現刪除重復記錄;還可以建臨時表來實現...這個只提到其中的幾種簡單實用的方法,希望可以和大家分享(以表employee為例)。
sql> desc employee
name null? type
emp_id number(10)
emp_name varchar2(20)
salary number(10,2)
可以通過下面的語句查詢重復的記錄:
sql> select * from employee;
emp_id emp_name salary
1 sunshine 10000
1 sunshine 10000
2 semon 20000
2 semon 20000
3 xyz 30000
2 semon 20000
sql> select distinct * from employee;
emp_id emp_name salary
1 sunshine 10000
2 semon 20000
3 xyz 30000
sql> select * from employee group by emp_id,emp_name,salary having count (*)>1
emp_id emp_name salary
1 sunshine 10000
2 semon 20000
sql> select * from employee e1
where rowid in (select max(rowid) from employe e2
where e1.emp_id=e2.emp_id and
e1.emp_name=e2.emp_name and e1.salary=e2.salary);
emp_id emp_name salary
1 sunshine 10000
3 xyz 30000
2 semon 20000
2. 刪除的幾種方法:
(1)通過建立臨時表來實現
sql>create table temp_emp as (select distinct * from employee)
sql> truncate table employee; (清空employee表的數據)
sql> insert into employee select * from temp_emp; (再將臨時表里的內容插回來)
( 2)通過唯一rowid實現刪除重復記錄.在oracle中,每一條記錄都有一個rowid,rowid在整個數據庫中是唯一的,rowid確定了每條記錄是在oracle中的哪一個數據文件、塊、行上。在重復的記錄中,可能所有列的內容都相同,但rowid不會相同,所以只要確定出重復記錄中那些具有最大或最小rowid的就可以了,其余全部刪除。
sql>delete from employee e2 where rowid not in (
select max(e1.rowid) from employee e1 where
e1.emp_id=e2.emp_id and e1.emp_name=e2.emp_name and e1.salary=e2.salary);--這里用min(rowid)也可以。
sql>delete from employee e2 where rowid <(
select max(e1.rowid) from employee e1 where
e1.emp_id=e2.emp_id and e1.emp_name=e2.emp_name and e1.salary=e2.salary);
(3)也是通過rowid,但效率更高。
sql>delete from employee where rowid not in (
select max(t1.rowid) from employee t1 group by t1.emp_id,t1.emp_name,t1.salary);--這里用min(rowid)也可以。
emp_id emp_name salary
1 sunshine 10000
3 xyz 30000
2 semon 20000
新聞熱點






疑難解答